Обработка звука в Scilab: как реализовать спектральное вычитание
В данной статье обсуждается методика, в которой вычитание в частотной области используется для избирательного подавления компонентов шума в аудиосигнале.
Вспомогательная информация
- Учимся жить в частотной области (из первой главы миниучебника о радиочастотном анализе и проектировании)
Предыдущие статьи о цифровой обработке сигналов в Scilab
- Основы цифровой обработки сигналов (ЦОС, DSP) для синусоидальных сигналов с Scilab
- Как выполнить анализ в частотной области с помощью Scilab
- Как использовать Scilab для анализа амплитудно-модулированных РЧ сигналов
- Как использовать Scilab для анализа частотно-модулированных РЧ сигналов
- Как выполнить частотную модуляцию оцифрованным аудиосигналом с помощью Scilab
- Цифровая обработка сигналов в Scilab: как удалить шум в аудиозаписи с помощью фильтров обработки звука
В предыдущей статье для подавления шумовых компонентов в аудиозаписи голоса мы использовали фильтр. Этот подход довольно неэффективен. Одна из проблем заключается в том, что вы не можете подавлять шумовые частоты, близкие к частотам сигнала, особенно если ваша система не может реалистично реализовать фильтр очень высокого порядка. Другая проблема заключается в том, что действие фильтрации не является избирательным: она не различает сигнал и шум в пределах заданной полосы частот, и, следовательно, характеристики голоса изменяются нежелательными способами.
В данной статье мы рассмотрим другую методику снижения шума. Она называется спектральным вычитанием и состоит из следующих шагов:
- Сделать аудиозапись, содержащую только фоновый шум (или извлечь из исходной записи фрагмент, содержащий только шум).
- Создать спектр шума, вычислив FFT и сохранив данные об амплитуде.
- (Могут быть выполнены дополнительные шаги, а именно усреднение и предварительная отрисовка, чтобы сделать шумовой спектр более эффективным средством уменьшения шума.)
- Создать спектр аудиофайла с уменьшенным уровнем шума путем вычитания спектра шума из амплитуды результатов FFT исходной аудиозаписи.
- Вставить информацию о фазе в спектр с уменьшенным уровнем шума путем дублирования информации о фазе из результатов FFT исходной записи.
- Создать сигнал с уменьшенным шумом во временной области с помощью обратного быстрого преобразования Фурье.
Если вы немного запутались, не волнуйтесь – эти шаги будут обсуждаться более подробно, поскольку мы прокладываем путь через команды Scilab.
Кроме того, я собираюсь заранее предупредить вас, что спектральное вычитание в моем случае работает не очень хорошо. Оно сохранило качество голоса лучше, чем фильтрация, и диаграммы FFT подтверждают, что оно может удалять узкополосные шумовые компоненты так, как не может фильтрация. Однако уменьшение уровня шума было по некоторым причинам почти незаметным. Возможно, более сложная реализация принесет лучшие результаты, и, возможно, я напишу еще одну статью о спектральном вычитании, если найду способ сделать его более эффективным.
Создание спектра шума
Я дублировал настройки звука, используемые для создания исходного аудиофайла, а затем захватил около 60 секунд «тишины». Эта тишина стала шипением в аудиозаписи. Как вы увидите позже, длина записи шума должна быть такой же, как длина записи голоса. Моя запись голоса длится около 10 секунд, так зачем я записал 60 секунд шума? Ну, это была моя попытка включить усреднение в спектр шума:
[NoiseAudio, Fs] = wavread("C:\Users\Robert\Documents\Audio\Noise.wav");
NoiseAudio_1 = NoiseAudio(1:Fs*10);
NoiseAudio_2 = NoiseAudio(1+Fs*10:Fs*20);
NoiseAudio_3 = NoiseAudio(1+Fs*20:Fs*30);
...
NoiseAudio_6 = NoiseAudio(1+Fs*50:Fs*60);
NoiseAudio_1_FFTMag = abs(fft(NoiseAudio_1));
NoiseAudio_2_FFTMag = abs(fft(NoiseAudio_2));
...
NoiseAudio_6_FFTMag = abs(fft(NoiseAudio_6));
for k = 1:length(NoiseAudio_1_FFTMag)
> Noise_FFTMag(1,k) = (NoiseAudio_1_FFTMag(k) + NoiseAudio_2_FFTMag(k) + NoiseAudio_3_FFTMag(k) + NoiseAudio_4_FFTMag(k) + NoiseAudio_5_FFTMag(k) + NoiseAudio_6_FFTMag(k))/6;
> end
Поэтому я разделил 60-секундную запись на шесть 10-секундных фрагментов. Затем я вычислил спектр для каждого из них и усреднил и всех, чтобы создать конечный шумовой спектр. Использование усредненного шумового спектра действительно дало разницу в конечной аудиозаписи, хотя я бы не сказал, что общее качество было лучше.
Следующие графики показывают общую форму моего шумового спектра. Я не собираюсь преобразовывать горизонтальную ось в частоты, потому что на данный момент мы не думаем о реальных частотах. Мы рассматриваем спектр больше как обычный массив точек данных.
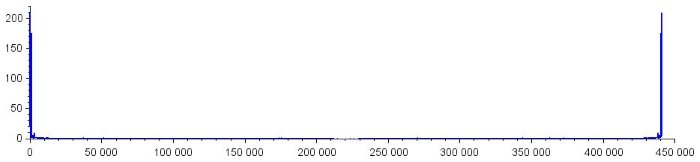
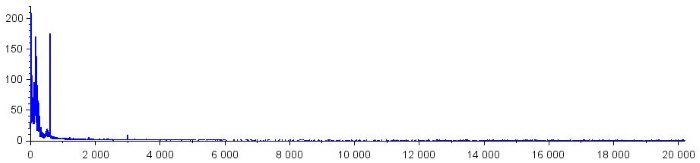
Выполнение вычитания
Этот шаг прост, если вы понимаете следующие две вещи. Во-первых, мы здесь работаем только с амплитудами FFT, а не с комплексными числами, которые являются исходным результатом вычисления FFT. Во-вторых, мы не можем иметь отрицательные значения амплитуды в нашем шумовом спектре. Это означает, что вам нужно проверить результаты вычитания на отрицательность и изменить все отрицательные значения на ноль.
[OriginalAudio, Fs] = wavread("C:\Users\Robert\Documents\Audio\OnceUponaMidnightDreary.wav");
OriginalAudio = OriginalAudio(1:Fs*10); // Укороченная запись точно до 10 секунд.
// Массив, содержащий результаты FFT исходной записи,
// и массив, содержащий шумовой спектр,
// должны быть одинаковой длины.
OriginalAudio_FFTMag = abs(fft(OriginalAudio));
for k = 1:length(OriginalAudio_FFTMag)
> FFTMag_NoiseSubtracted(1,k) = OriginalAudio_FFTMag(k) - Noise_FFTMag(k);
> if(FFTMag_NoiseSubtracted(1,k)) < 0
> FFTMag_NoiseSubtracted(1,k) = 0;
> end
> end
Восстановление фазы
Теперь у нас есть спектр амплитуд исходной записи с уменьшенным уровнем шума. К сожалению, мы не можем преобразовать звук обратно во временную область без фазы. Где мы найдем информацию о фазе этого спектра амплитуд, который мы просто искусственно создали, выполняя вычитание в частотной области? Есть только одно место: исходный сигнал с шумом. Итак, что мы действительно здесь делаем, это сохранение фазы Фурье у исходного сигнала и изменение его амплитуды Фурье. Во многих ситуациях сохранение исходной фазы не является проблематичным, поскольку шум связан прежде всего с амплитудой, а не с фазой.
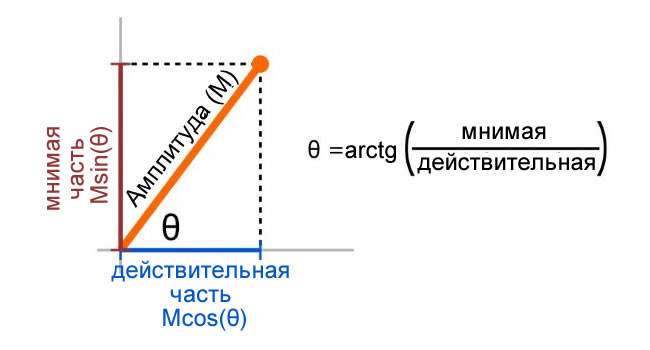
Результаты FFT исходного сигнала состоят из комплексных чисел, и конченые результаты FFT с уменьшенным шумом должны содержать комплексные числа, чтобы они могли быть успешно возращены во временную область с помощью команды ifft(). Таким образом, чтобы вставить в новый спектр фазовую информацию, мы должны сначала извлечь фазу из действительной и мнимой составляющих исходного спектра, а затем использовать значения амплитуды в новом спектре для создания нового массива комплексных чисел.
OriginalAudio_FFT = fft(OriginalAudio);
for k = 1:length(OriginalAudio_FFTMag)
> OriginalPhase = atan(imag(OriginalAudio_FFT(k)), real(OriginalAudio_FFT(k)));
> RealPart = FFTMag_NoiseSubtracted(k) * cos(OriginalPhase);
> ImagPart = FFTMag_NoiseSubtracted(k) * sin(OriginalPhase);
> FFT_NoiseSubtracted(1,k) = complex(RealPart, ImagPart);
> end
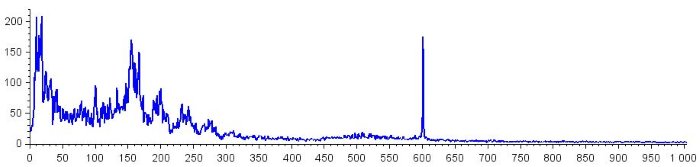
Следующие графики дают большую демонстрацию возможностей спектрального вычитания. Первый показывает всплеск шума 60 Гц (при значении 600 на горизонтальной оси), который присутствует в исходном сигнале. Во втором случае всплеск шума убран, а соседние спектральные компоненты заметно не пострадали.
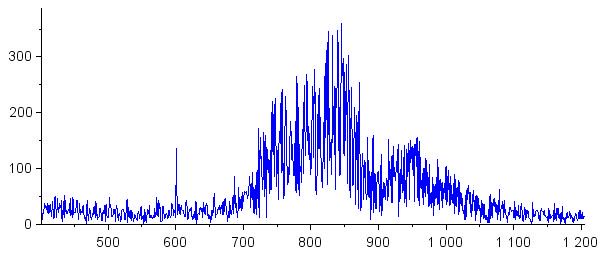
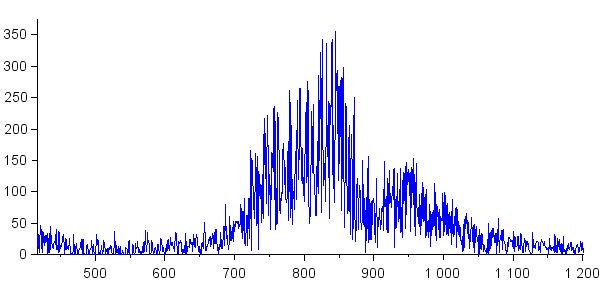
Возвращение во временную область
Теперь у нас есть модифицированный спектр, который готов к преобразованию в обычный аудиосигнал. Это выполняется с помощью обратного БПФ:
Audio_NoiseSubtracted = ifft(FFT_NoiseSubtracted);
Вот оригинальный и (теоретически) улучшенный аудиофайлы, чтобы вы могли составить собственное мнение об успешности спектрального вычитания:
Исходная аудиозапись
Аудиозапись после спектрального вычитания
Заключение
Как упоминалось выше, спектральное вычитание не сильно уменьшило уровень фоновых шумов. Когда я внимательно слушаю, я думаю, что замечаю какое-то улучшение, но это едва заметное изменение, и оно может быть связано прежде всего с качеством шума, а не с количеством. Однако спектральное вычитание также ввело неприятный артефакт, который особенно заметен в начале записи (прежде чем я начинаю говорить). Тем не менее, мой голос звучит одинаково в обеих записях, что является существенным улучшением по сравнению с подходом фильтрации. Если у кого-то есть идеи относительно того, как сделать спектральное вычитание более эффективным, оставляйте комментарии.