Объединение (union) в языке C для упаковки и распаковки данных
Рассмотрим упаковку и распаковку данных с помощью объединений (union) в языке C.
В предыдущей статье мы обсуждали, что первоначальное применение объединений создавало общую область памяти для взаимоисключающих переменных. Однако со временем программисты широко использовали объединения для совершенно другого применения: извлечения небольших частей данных из более крупного объекта данных. В данной статье мы рассмотрим это конкретное применение объединений более подробно.
Использование объединений для упаковки/распаковки данных
Члены объединения хранятся в общей области памяти. Это ключевая особенность, которая позволяет нам находить интересные применения для объединений.
Рассмотрим объединение, приведенное ниже:
union {
uint16_t word;
struct {
uint8_t byte1;
uint8_t byte2;
};
} u1;
Внутри этого объединения содержится два члена. Первый член, “word”, является двухбайтовой переменной. Второй член – это структура из двух однобайтовых переменных. Два байта, выделенные для объединения распределяются между двумя его членами.
Выделенное пространство памяти может быть таким, как показано ниже на рисунке 1.
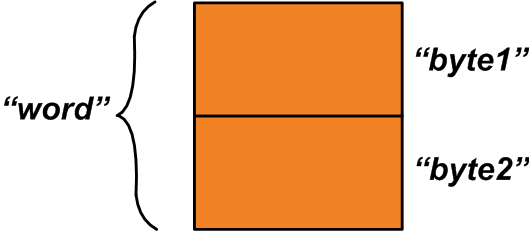
В то время как переменная “word” относится ко всему выделенному пространству памяти, переменные “byte1” и “byte2” относятся к однобайтовым областям, которые составляют переменную “word”. Как мы можем использовать эту особенность? Предположим, что у вас есть две однобайтовые переменные, “x” и “y”, которые должны быть объединены для получения одной двухбайтовой переменной.
В этом случае вы можете использовать приведенное выше объединение и присвоить значения “x” и “y” членам структуры следующим образом:
u1.byte1 = y;
u1.byte2 = x;
Теперь мы можем прочитать у объединения член “word”, чтобы получить двухбайтовую переменную, состоящую из переменных “x” и “y” (рисунок 2).
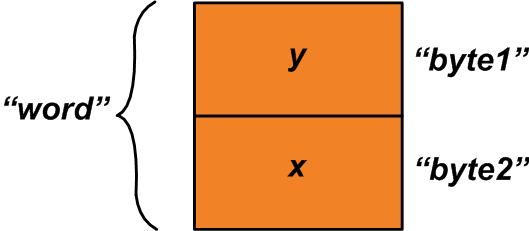
В приведенном выше примере показано использование объединений для упаковки двух однобайтовых переменных в одну двухбайтовую переменную. Мы также можем сделать и обратное: записать двухбайтовое значение в “word” и распаковать его в две однобайтовые переменные, прочитав переменные “x” и “y”. Запись значения в один член объединения и чтение другого члена иногда называется «каламбуром данных» («data punning»)
Порядок байтов процессора
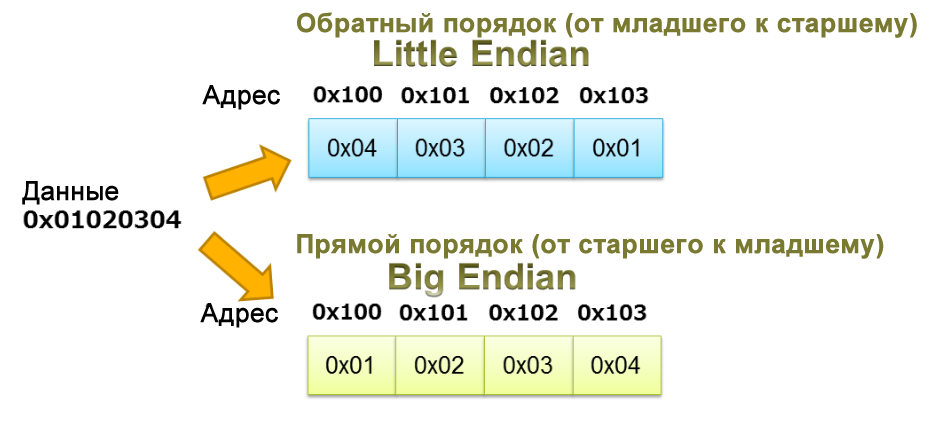
При использовании объединений для упаковки/распаковки данных мы должны быть осторожны с порядком байтов (endianness) процессора. Как обсуждалось в статье о порядке байтов, этот термин определяет порядок, в котором байты объекта хранятся в памяти. Процессор может быть с обратным порядком (от младшего к старшему, little endian) или с прямым порядком (от старшего к младшему, big endian). В системах с прямым порядком байтов (big endian) данные хранятся таким образом, что байт, содержащий старший значащий байт, имеет самый младший адрес памяти. В системах с обратным порядком байтов (little endian) байт, содержащий младший значащий байт, сохраняется первым.
Пример, изображенный на рисунке 3, иллюстрирует хранение последовательности 0x01020304 при обратном и при прямом порядках байтов.
Давайте поэкспериментируем с объединением из предыдущего раздела.
#include <stdio.h>
#include <stdint.h>
int main()
{
union {
struct{
uint8_t byte1;
uint8_t byte2;
};
uint16_t word;
} u1;
u1.byte1 = 0x21;
u1.byte2 = 0x43;
printf("Word is: %#X", u1.word);
return 0;
}
Запустив данный код, я получаю следующий вывод
Word is: 0X4321
Он показывает, что первый байт общего пространства памяти (“u1.byte1”) используется для хранения наименьшего значащего байта (0x21) переменной “word”. Другими словами, процессор, который я использую для выполнения кода, использует обратный порядок байтов (little endian).
Как видите, это конкретное применение объединений может демонстрировать поведение, зависящее от реализации. Тем не менее, это не должно быть серьезной проблемой, потому что при таком низкоуровневом кодировании мы обычно знаем порядок байтов процессора. В случае если мы не знаем подробностей, мы можем использовать приведенный выше код, чтобы узнать, как данные организованы в памяти.
Альтернативное решение
Вместо использования объединений для выполнения упаковки или распаковки данных мы также можем использовать побитовые операторы. Например, мы можем использовать следующий код для совмещения двух однобайтовых переменных, “byte3” и “byte4”, и создания одной двухбайтовой переменной (“word2”):
word2 = (((uint16_t) byte3) << 8 ) | ((uint16_t) byte4);
Давайте сравним вывод этих двух решений в случаях с прямым и обратным порядками байтов. Рассмотрим код, приведенный ниже:
#include <stdio.h>
#include <stdint.h>
int main()
{
union {
struct {
uint8_t byte1;
uint8_t byte2;
};
uint16_t word1;
} u1;
u1.byte1 = 0x21;
u1.byte2 = 0x43;
printf("Word1 is: %#X\n", u1.word1);
uint8_t byte3, byte4;
uint16_t word2;
byte3 = 0x21;
byte4 = 0x43;
word2 = (((uint16_t) byte3) << 8 ) | ((uint16_t) byte4);
printf("Word2 is: %#X \n", word2);
return 0;
}
Если мы скомпилируем этот код для процессора с прямым порядком байтов (big endian), такого как TMS470MF03107, результат будет следующим:
Word1 is: 0X2143
Word2 is: 0X2143
Однако если мы скомпилируем этот код для процессора с обратным порядком байтов (little endian), такого как STM32F407IE, результат будет следующим:
Word1 is: 0X4321
Word2 is: 0X2143
В то время как основанный на объединении код демонстрирует аппаратно-зависимое поведение, способ, основанный на операции сдвига, приводит к одному и тому же результату независимо от порядка байтов процессора. Это связано с тем, что при последнем подходе мы присваиваем значение переменной по имени (“word2”), и компилятор заботится об организации памяти, используемой устройством. А с помощью метода на основе объединения мы меняем значение байтов, которые составляют переменную “word1”.
Хотя основанный на объединении метод демонстрирует аппаратно-зависимое поведение, его преимущество заключается в том, что он более читабелен и удобен в поддержке. Вот почему многие программисты предпочитают использовать объединения в таком применении.
Практический пример «каламбура данных»
Выполнить упаковку или распаковку данных нам может потребоваться при работе с обычными последовательными протоколами связи. Рассмотрим протокол последовательной связи, который отправляет/принимает один байт данных во время каждого сеанса связи. Пока мы работаем с однобайтовыми переменными, данные передавать легко, но что если у нас есть структура произвольного размера, которая должна проходить через канал связи? В этом случае мы должны каким-то образом представить наш объект данных в виде массива переменных размером по одному байту. Затем на стороне получателя мы можем соответствующим образом их упаковать и восстановить исходную структуру.
Например, предположим, что нам нужно отправить канал связи UART переменную типа float, “f1”. Переменная типа float обычно занимает четыре байта. Следовательно, мы можем использовать следующее объединение в качестве буфера для извлечения четырех байтов “f1”.
union {
float f;
struct {
uint8_t byte[4];
};
} u1;
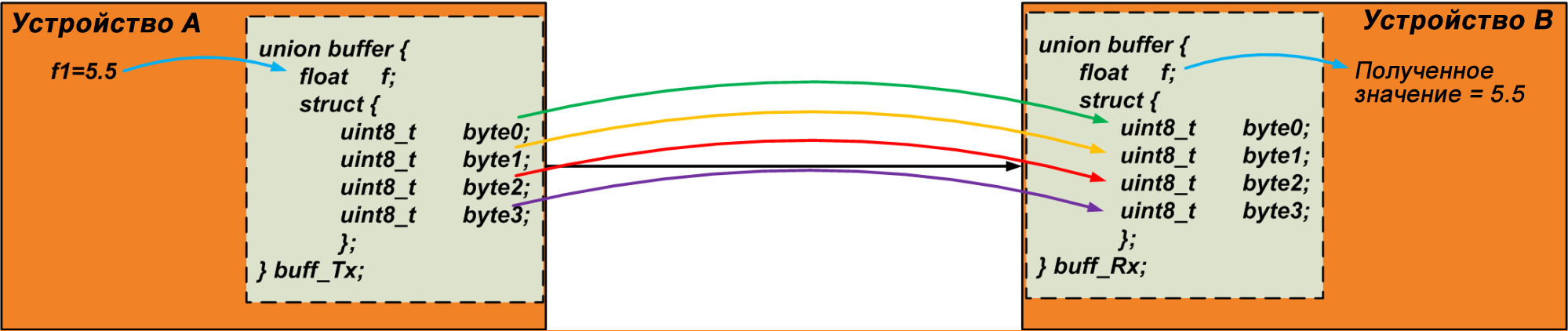
Передатчик записывает переменную “f1” в член объединения с типом float. Затем он считывает массив “byte” и отправляет эти байты по каналу связи. Получатель делает обратное: он записывает полученные данные в массив “byte” своего собственного объединения и считывает переменную объединения с типом float как полученное значение. Мы могли бы использовать этот метод для передачи объекта данных произвольного размера. Следующий код может использоваться в качестве простого теста для проверки этого метода.
#include <stdio.h>
#include <stdint.h>
int main()
{
float f1=5.5;
union buffer {
float f;
struct {
uint8_t byte[4];
};
};
union buffer buff_Tx;
union buffer buff_Rx;
buff_Tx.f = f1;
buff_Rx.byte[0] = buff_Tx.byte[0];
buff_Rx.byte[1] = buff_Tx.byte[1];
buff_Rx.byte[2] = buff_Tx.byte[2];
buff_Rx.byte[3] = buff_Tx.byte[3];
printf("The received data is: %f", buff_Rx.f);
return 0;
}
Рисунок 4, приведенный ниже, визуализирует обсуждаемый метод. Обратите внимание, что байты передаются последовательно.
Заключение
В то время как изначальное применение объединений создавало общую область памяти для взаимоисключающих переменных, с течением времени программисты широко использовали объединения для совершенно другого применения: для упаковки/распаковки данных. Это конкретное применение объединений включает в себя запись значения в один член объединения и чтение другого его члена.
«Каламбур данных» («data punning») или использование объединений для упаковки/распаковки данных может привести к аппаратно-зависимому поведению. Однако его преимущество заключается в том, что оно более читабельно и удобно в поддержке. Вот почему многие программисты предпочитают использовать в этом случае объединения. «Каламбур данных» может быть особенно полезен, когда у нас есть объект данных произвольного размера, который должен передаваться через канал последовательной связи.