Понимание памяти: как использовать структуры при программировании для встраиваемых систем на языке C
Рассмотрим, как процессоры обращаются к памяти. Узнаем больше о структурах в языке C и о том, как их использовать.
В данной статье сначала будет объяснено понятие гранулярности доступа к памяти, чтобы мы могли выработать базовое понимание того, как процессор обращается к памяти. Затем мы более подробно рассмотрим концепцию выравнивания данных и исследуем распределение памяти для нескольких примеров структур.
В предыдущей статье о структурах в языке C для встраиваемых систем мы увидели, что перестановка членов в структуре может изменить объем памяти, необходимый для хранения структуры. Мы также видели, что компилятор обладает некоторыми ограничениями при выделении памяти для членов структуры. Эти ограничения, называемые требованиями к выравниванию данных, позволяют процессору более эффективно обращаться к переменным за счет некоторого потраченного впустую пространства памяти (известного как «заполнение»), которое может появиться в распределении памяти.
Стоит отметить, что система памяти компьютера может быть гораздо более сложной, чем представленная здесь. Цель данной статьи – обсудить некоторые основные концепции, которые могут быть полезны при программировании встраиваемых систем.
Гранулярность доступа к памяти
Обычно мы представляем память как совокупность однобайтовых ячеек, как показано на рисунке 1. Каждая из этих ячеек имеет уникальный адрес, который позволяет нам получить доступ к данным по этому адресу.
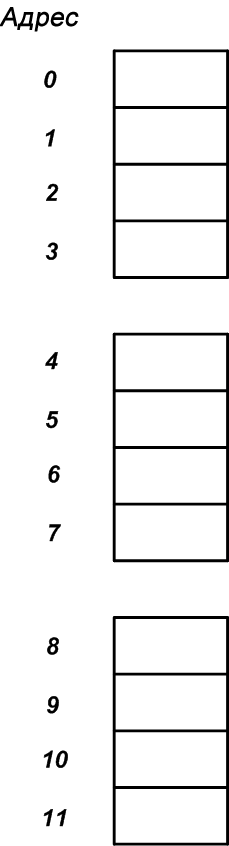
Однако процессор обычно обращается к памяти кусками размером более одного байта. Например, процессор может получать доступ к памяти в виде четырехбайтовых блоков. В этом случае мы можем представить 12 последовательных байтов на рисунке 1, как показано ниже на рисунке 2.
Вы можете задаться вопросом, в чем разница между этими двумя способами обработки памяти. На рисунке 1 процессор читает и записывает в память за раз по одному байту. Обратите внимание, что перед чтением ячейки памяти или записью в нее нам необходимо получить доступ к этой ячейке, и каждая процедура доступа к памяти занимает некоторое время. Предположим, что мы хотим прочитать первые восемь байтов на рисунке 1. Для каждого байта процессор должен получить доступ к памяти и прочитать ее. Следовательно, чтобы прочитать содержимое первых восьми байтов, процессору придется обращаться к памяти восемь раз.
На рисунке 2 процессор читает и записывает в память за раз четыре байта. Следовательно, чтобы прочитать первые четыре байта, процессор обращается к адресу 0 в памяти и считывает четыре последовательных ячейки хранения (адреса с 0 до 3). Точно так же, чтобы прочитать следующий четырехбайтовый фрагмент процессору необходимо получить доступ к памяти еще один раз. Он идет по адресу 4 и считывает ячейки хранения по адресам с 4 по 7 одновременно. Для блоков размером в байт требуется восемь обращений к памяти, чтобы прочитать восемь последовательных байтов в памяти. Однако для распределения на рисунке 2 требуется только две процедуры доступа к памяти. Как упоминалось выше, каждая процедура доступа к памяти занимает некоторое время. Поскольку конфигурация памяти, показанная на рисунке 2, уменьшает количество обращений, она может привести к большей эффективности обработки.
Размер данных, который процессор использует при доступе к памяти, называется гранулярностью доступа к памяти. На рисунке 2 показана система с четырехбайтовой гранулярностью доступа к памяти.
Границы доступа к памяти
Существует еще один важный метод, который разработчики аппаратного обеспечения часто используют, чтобы сделать систему обработки более эффективной: они ограничивают процессор так, чтобы он мог обращаться к памяти только на определенных границах. Например, процессор может иметь доступ к памяти, представленной на рисунке 2, только на четырехбайтовых границах, как показано красными стрелками на рисунке 3.
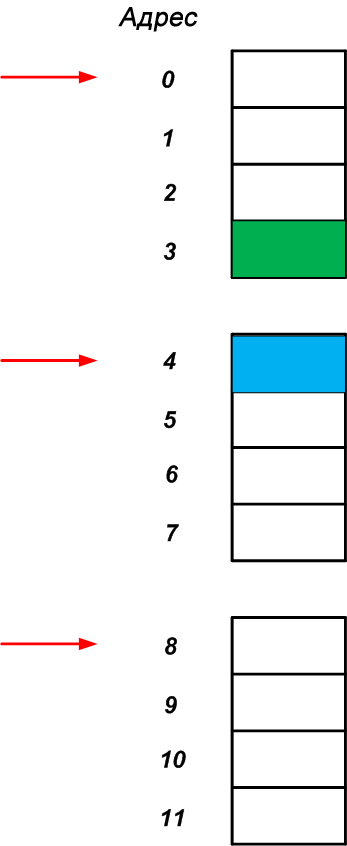
Будет ли это ограничение границами делать систему значительно более эффективной? Давайте рассмотрим подробнее. Предположим, что нам нужно прочитать содержимое областей памяти с адресами 3 и 4 (на рисунке 3 обозначены зеленым и синим прямоугольниками). Если процессор бы мог прочитать четырехбайтовый фрагмент, начиная с произвольного адреса, мы могли бы получить доступ к адресу 3 и прочитать две нужных ячейки памяти за один раз доступа к памяти. Однако, как упоминалось выше, процессор не может напрямую получить доступ к произвольному адресу; он обращается к памяти только на определенных границах. Итак, как процессор будет считывать содержимое ячеек по адресам 3 и 4, если он может получить доступ только к четырехбайтовым границам?
Из-за ограничений границ доступа к памяти процессор должен получить доступ к ячейке памяти с адресом 0 и прочитать четыре последовательных байта (адреса с 0 по 3). Затем он должен использовать операции сдвига для отделения содержимого адреса 3 от других трех байтов (адреса с 0 по 2). Аналогично процессор может получить доступ к адресу 4 и прочитать другой четырехбайтовый фрагмент по адресам с 4 по 7. Наконец, операции сдвига могут снова использоваться для отделения нужного байта (синего прямоугольника) от других трех байтов.
Если бы не было ограничения границ доступа к памяти, мы могли бы прочитать ячейки по адресам 3 и 4 за одну процедуру доступа к памяти. Однако ограничение границ заставляет процессор обращаться к памяти дважды. Так зачем нам ограничивать доступ к памяти определенными границами, если это усложняет манипулирование данными? Ограничение доступа к памяти границами существует потому, что определенные предположения об адресе могут упростить конструкцию оборудования. Например, предположим, что для адресации всех байтов в блоке памяти требуется 32 бита. Если мы ограничим адрес четырехбайтовыми границами, то два младших бит 32-битного адреса всегда будут равны нулю (поскольку адрес всегда будет делиться на четыре без остатка). Следовательно, мы сможем использовать 30 бит для адресации памяти с 232 байтами
Выравнивание данных
Теперь, когда мы знаем, как базовый процессор обращается к памяти, мы можем обсудить требования к выравниванию данных. Как правило, любой K-байтовый тип данных языка C должен иметь адрес, кратный K. Например, четырехбайтовый тип данных может храниться только по адресам 0, 4, 8, ...; его нельзя хранить по адресам 1, 2, 3, 5, ... . Такие ограничения упрощают конструкцию аппаратного интерфейса между процессором и системой памяти.
В качестве примера рассмотрим процессор с четырехбайтовой гранулярностью доступа к памяти, который может обращаться к памяти только на четырехбайтовых границах. Предположим, что четырехбайтовая переменная хранится по адресу 1, как показано на рисунке 4 (четыре байта соответствуют четырем разным цветам). В этом случае нам понадобятся два обращения к памяти и некоторая дополнительная работа для чтения невыровненных четырехбайтовых данных (под «невыровненными» я подразумеваю, что они разбиты на два четырехбайтовых блока). Процедура показана на рисунке.
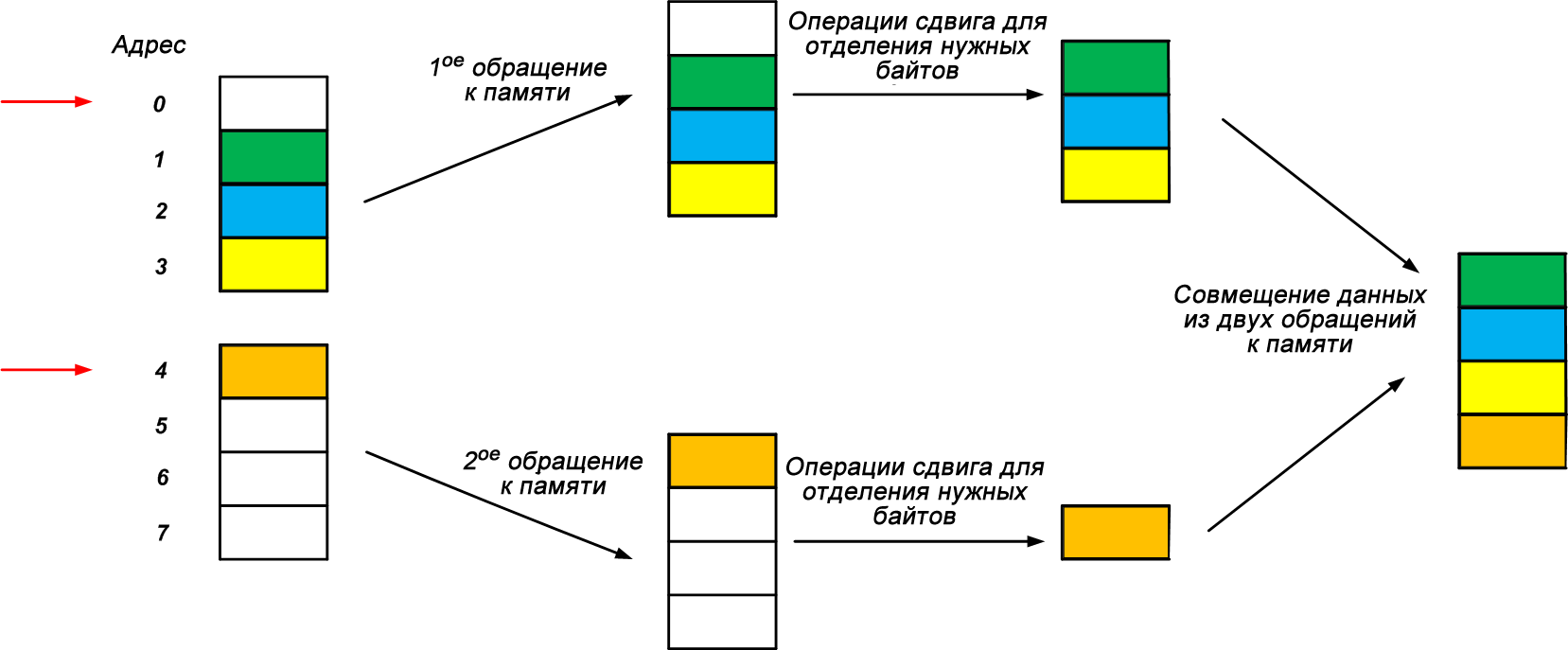
Однако, если мы храним четырехбайтовую переменную по любому адресу, кратному 4, нам потребуется только одна процедура доступа к памяти, чтобы изменить данные или прочитать их.
Вот почему хранение K-байтовых типов данных по адресу, кратному K, может сделать систему более эффективной. Следовательно, переменные "char" языка C (которые требуют только одного байта) могут храниться по любому байтовому адресу, но двухбайтовая переменная должна храниться по четным адресам. Четырехбайтовые типы должны начинаться с адресов, которые делятся на 4 без остатка, а восьмибайтовые типы данных должны храниться по адресам, которые делятся без остатка на 8. Например, предположим, что на конкретной машине переменным "short" требуется два байта, типы "int" и "float" занимают четыре байта, а "long", "double" и указатели занимают восемь байтов. Каждый из этих типов данных обычно должен иметь адрес, кратный K, где K задается в следующей таблице.
| Тип данных | K |
|---|---|
char |
1 |
short |
2 |
int, float |
4 |
long, double, char* |
8 |
Обратите внимание, что размер разных типов данных может варьироваться в зависимости от компилятора и архитектуры машины. Оператор sizeof() будет лучшим способом для определения фактического размера типа данных.
Распределение памяти для структуры
Теперь давайте рассмотрим распределение памяти для структуры. Рассмотрим компилирование следующей структуры для 32-разрядной машины:
struct Test2{
uint8_t c;
uint32_t d;
uint8_t e;
uint16_t f;
} MyStruct;
Мы знаем, что для хранения членов структуры будут выделены четыре области памяти, и порядок расположения областей памяти будет соответствовать порядку объявления членов. Первый член является однобайтовой переменной и может храниться по любому адресу. Следовательно, этой переменной будет выделена первая доступная область хранения. Предположим, что, как показано на рисунке 5, компилятор выделит этой переменной адрес 0. Следующий член является четырехбайтовым типом данных и может храниться по адресам, кратным 4. Первым доступным местом хранения является адрес 4. Однако для этого необходимо оставить адреса 1, 2 и 3 неиспользованными. Как видите, требование выравнивания данных приводит к некоторому потерянному пространству (или заполнению) в распределении памяти.
Следующий член – это e, который является однобайтовой переменной. Этой переменной может быть назначено первое доступное место хранения (адрес 8 на рисунке 5). Далее мы доходим до f, который является двухбайтовой переменной. Он может храниться по адресу, который делится на 2. Первое доступное пространство – это адрес 10. Как вы можете видеть, для удовлетворения требований выравнивания данных появится дополнительное заполнение.
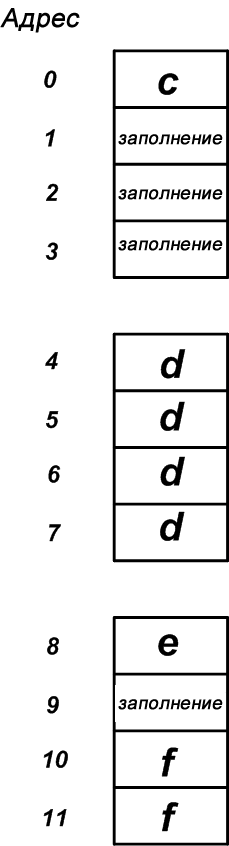
Мы ожидали, что структура будет занимать 8 байтов, но на самом деле она потребовала 12 байтов. Интересно, что если нам известно о требованиях к выравниванию данных, мы сможем изменить порядок членов в структуре и повысить эффективность использования памяти. Например, давайте перепишем приведенную выше структуру, как показано ниже, где члены упорядочены от самого большого до самого маленького.
struct Test2 {
uint32_t d;
uint16_t f;
uint8_t c;
uint8_t e;
} MyStruct;
На 32-разрядной машине распределение памяти для объявленной выше структуры, вероятно, будет выглядеть как схема, изображенная на рисунке 6.
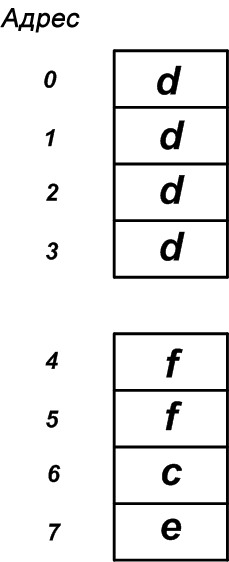
В то время как первая структура требовала 12 байтов, новая модифицированная структура требует только 8 байтов. Это значительное улучшение, особенно в контексте встроенных процессоров с ограниченным объемом памяти.
Также обратите внимание, что после последнего члена структуры могут быть несколько байтов заполнения. Общий размер структуры должен делиться на размер ее наибольшего члена. Рассмотрим следующую ситуацию:
struct Test3 {
uint32_t c;
uint8_t d;
} MyStruct2;
В этом случае распределение памяти будет таким, как показано на рисунке 7. Как вы можете видеть, в конце выделенной памяти добавляются три байта заполнения, чтобы увеличить размер структуры до 8 байт. Это сделает размер структуры кратным размеру наибольшего члена структуры (член c, который является четырехбайтовой переменной).
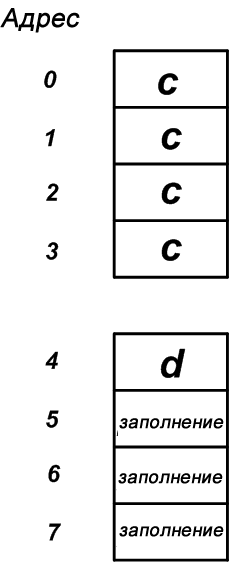
Подведем итоги
- Процессор обычно обращается к памяти кусками размером более одного байта. Это может повысить эффективность системы.
- Гранулярность доступа процессора к памяти – это размер данных, который используется, когда процессор обращается к памяти.
- Процессор может быть ограничен доступом к памяти только на определенных границах (например, на четырехбайтовых границах).
- Это ограничение доступа к памяти границами существует потому, что определенные предположения об адресе могут упростить конструкцию оборудования.
- Как правило, любой K-байтовый тип данных языка C должен иметь адрес, кратный K. Такие ограничения упрощают конструкцию аппаратного интерфейса между процессором и системой памяти.
- Требование выравнивания данных приводит к некоторому потерянному пространству (или заполнению) в распределении памяти.
- После последнего члена структуры может быть несколько байтов заполнения. Общий размер структуры должен быть кратен размеру ее наибольшего члена.