Технология двойной буферизации UART, дружественная к прерываниям
UART – отличный протокол передачи как для любительских, так и профессиональных проектов, но в критически важных системах UART может быть коварен.
UART (Universal Asynchronous Reception Transmission, универсальная асинхронная приемопередача) – популярный протокол для микроконтроллеров для взаимодействия с другими микроконтроллерами и компьютерами. Проекты с низкими скоростями передачи данных, использующие высокоскоростные микроконтроллеры, обычно не имеют проблем с UART. Однако на более высоких скоростях, или если микроконтроллер выполняет множество задач, могут возникнуть серьезные проблемы, включая пропущенные байты и порядок этих байтов. Даже в системе, управляемой прерываниями, бывает очень трудно сохранить порядок байтов. В данной статье будет рассмотрен метод, разработанный для решения этого типа проблем, называемый двойной буферизацией UART.
Примечание: технический жаргон (push (проталкивание) и pop (выталкивание))
Для тех, кто не знаком со стеками, проталкивание (push) данных означает, что данные помещаются в буфер, а выталкивание (pop) – удаление данных из буфера.
Объяснение проблемы
Представьте себе обработчик прерывания, который выполняет одну задачу: после получения байта по UART он сохраняет этот байт в массив буфера и увеличивает счетчик количества байтов totalBytes.
isr_routine()
{
if(UART_RECEIVE)
{
buffer[totalBytes] = UART_GET;
totalBytes++;
}
}
Пока этот массив заполняется данными, наша основная программа берет байты из этого буфера, а затем уменьшает значение счетчика totalBytes.
program()
{
do{
if(totalBytes > 0)
{
cout << buffer[totalBytes];
totalBytes--;
}
}while(1);
}
Пока основная программа берет байты из буфера быстрее, чем они отправляются, порядок байтов будет сохраняться. Однако, если программа не может быстро вывести байты, и байты добавляются в середине этого цикла (помните, что прерывание имеет больший приоритет над основным циклом), тогда порядок байтов будет потерян. Но что такое «порядок байтов»?
Порядок байтов
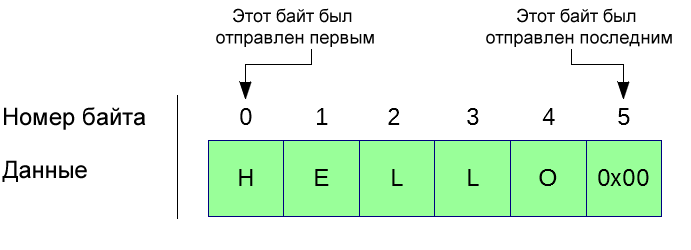
Порядок байтов можно рассматривать как временную шкалу, на которой байты упорядочены хронологически. Первый полученный байт должен быть первой частью данных, подлежащих обработке, а последний полученный байт должен быть последним в обработке. Таким образом, в этом примере, если устройство отправляет через UART «Hello», и наша основная программа достаточно быстра, вывод cout (при условии, что у нас есть дисплей) также должен быть «Hello», а не «elHlo» или какую-либо другую комбинацию.
Итак, рассмотрев, что такое порядок байтов, давайте теперь посмотрим, как этот «порядок» теряется, если основная программа не может выводить данные из буфера быстрее, чем ISR (обработчик прерывания) помещает их туда. Для примера предположим, что за время, затрачиваемое нашей программой на получение одного байта из буфера, обработчик прерывания поместит туда два байта, переданные через UART. Как будет выглядеть вывод cout? На выходе будет выведено «elolH». Как это произошло?
- UART быстро отправляет первые два байта, «He»;
- основная программа берет один байт, расположенный в конце, «e»;
- к этому времени UART отправил еще два байта, «ll»;
- основная программа снова берет последний байт, «l»;
- UART отправляет последний байт, «o»;
- основная программа выводит данные из массива, начиная с конца к началу, «olH»;
- в результате получаем «elolH».
Мало того, что данные потеряли свой порядок, но он даже не стал обратным! Чтение байтов в обратном порядке НЕ решает проблему. Даже если вы читаете от первого элемента до последнего, вы не можете установить значение totalBytes, потому что ISR может остановить программу непосредственно перед изменением значения, поместить байт в конец массива, и затем, по возвращении, основная программа может сбросить значение totalBytes (тем самым потеряв этот отправленный байт). Если программа не изменяет значение totalBytes из-за потенциальной проблемы с вмешательством обработчика прерывания, буфер может переполниться.
Существуют обходные пути, такие как использование циклических буферов, несколько счетчиков и сортировка массива, но самый простой вариант (и один из лучших) – использование двойного буфера.
Двойной буфер
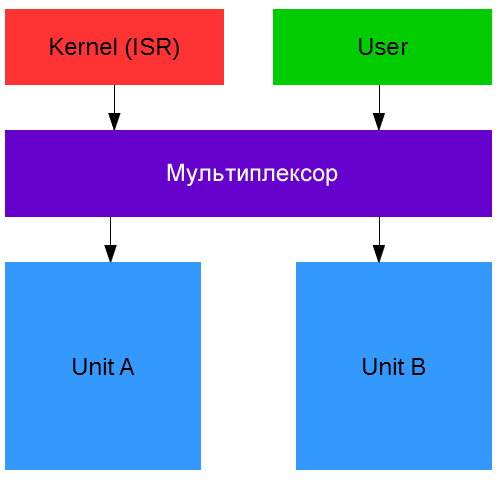
Двойной буфер можно рассматривать как два полностью отдельных блока (Unit), где обработчик прерывания работает с одним блоком, а программа – с другим. Для моделирования обработчик прерывания будет называться «Kernel» (ядро), а функции и программы, которые не выполняют обработку прерывания, будут называться «User» (пользователь) (они используют данные, а ядро Kernel обрабатывает аппаратное обеспечение).
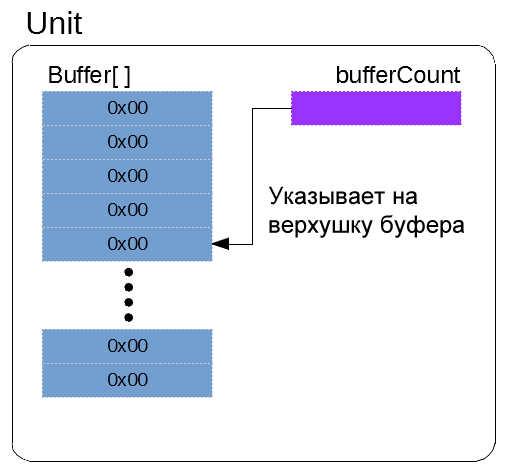
Каждый блок Unit имеет две переменные: массив buffer[] и счетчик bufferCounter. Буфер сохраняет данные UART по мере их поступления, а bufferCount содержит количество переданных данных. Этот счетчик можно использовать двумя способами:
- определять количество данных в буфере;
- определять куда вставлять / откуда извлекать данные буфера.
Примечание: самый простой способ программирования блоков Unit и мультиплексора – использование многомерного буфера и многомерного буфера счетчика.
// Каждый элемент многомерного массива – это блок Unit
buffer[2][32]
bufferCounter[2][1]
// Переменные блока Unit A
buffer[0][x]
bufferCounter[0][x]
// Переменные блока Unit B
buffer[1][x]
bufferCounter[1][x]
Селекторы блоков Unit для User и Kernel выполняются с помощью двух переменных uartKernel и uartUser. Каждое из этих значений всегда противоположно другому. Ниже приведена таблица истинности для этих значений:
| uartUser | uartKernel |
|---|---|
| 1 | 0 |
| 0 | 1 |
Мультиплексор решает, какой блок Unit будет направлен на ядро Kernel, а какой – на пользователя User (мультиплексор может находиться только в двух состояниях).
- состояние A приводит к тому, что Kernel использует Unit A, а User использует Unit B;
- состояние B приводит к тому, что Kernel использует Unit B, а User использует Unit A.
Мультиплексор можно переключить, вызвав функцию switchBuffers(). Она вызывается не при каждом завершении чтения байта из буфера, а только после того, как все данные в этом буфере обработаны, и программа готова получить дополнительную информацию от UART.
Когда User считывает массив, используя следующий код, байты идут в правильном порядке.
for(int i = 0; i < bufferCounter[uartUser]; i++)
{
cout << buffer[uartUser][i];
}
Для помещения данных в буфер Kernel использует следующий код.
isr_routine()
{
if(UART_RECEIVE)
{
buffer[uartKernel][bufferCounter[uartKernel]] = UART_GET;
bufferCounter[uartKernel]++;
}
}
Поскольку значения uartUser и uartKernel всегда разные (1 и 0), это означает, что User и Kernel всегда будут обращаться к разным буферам и счетчикам. Итак, как мы передаем информацию от ядра Kernel к пользователю User? Всё, что нам нужно сделать, – это переключить значения uartUser и uartKernel, чтобы они указывали на буферы и счетчики другого. Поэтому, когда User читает новые данные, Kernel может продолжать запись в неиспользуемый буфер. Чтобы выполнить это переключение, всё, что должен сделать User (прежде чем обрабатывать новые данные), – это вызвать switchBuffers().
SwitchBuffers()
{
uartUser = (!uartUser) & 0x01;
uartKernel = (!uartKernel) & 0x01;
// Необходимо сбросить счетчик для обработчика прерывания
bufferCounter[uartKernel] = 0;
}
Итак, давайте посмотрим на эту технологию двойной буферизации в сценарии, когда микроконтроллер находится под большой нагрузкой, и UART передает потоковые данные со скоростью, вдвое больше той, с которой программа могла бы справиться. Как и раньше, UART будет передавать «Hello», а программа будет печатать символы.
- UART выдает «He» в Kernel – байты помещаются в Unit A;
- программа вызывает
switchBuffers. Программа печатает «H» из Unit A; - UART выдает «ll» в Kernel – байты помещаются в Unit B;
- программа всё еще обрабатывает массив и печатает «e» из Unit A;
- UART выдает «o» в Kernel – байт помещается в Unit B;
- программа обработала Unit A и переключает буферы – программа печатает «l»;
- программа всё еще обрабатывает массив и печатает «l» из Unit B;
- программа всё еще обрабатывает массив и печатает «o» из Unit B.
Метод двойной буферизации сохранил обработчик прерывания и основную программу полностью отдельными, позволил нам сохранить порядок и создал очень простой код с возможностью для больших буферов. Не потребовалась ни какая сортировка массивов, обработчику прерывания не нужно было перемещать элементы для сохранения порядка, и не потребовалось сложной циклической буферизации.