Многопоточность в C++. Основные понятия
Введение
Разработчики часто сталкиваются с необходимостью разработки многопоточных приложений, поэтому вопросы многопоточности требуют детального изучения. Давайте познакомимся с основными терминами, используемыми в источниках информации о многопоточности, рассмотрим задачи и проблемы многопоточности и изучим средства стандартной библиотеки C++, которые помогут создавать многопоточные приложения.
Основные определения
Многозадачность и многопоточность
Многозадачность (multitasking) – свойство операционной системы или среды выполнения обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких задач.
Многопоточность (multithreading) – свойство платформы (например, операционной системы, виртуальной машины и т. д.) или приложения, состоящее в том, что процесс, порождённый в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно», то есть без предписанного порядка во времени. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
По-настоящему параллельное выполнение задач возможно только в многопроцессорной системе, поскольку только в них присутствуют несколько системных конвейеров для исполнения команд.
В однопроцессорной многозадачной системе поддерживается так называемое псевдопараллельное исполнение, при котором создается видимость параллельной работы нескольких процессов. В таких системах, однако, процессы выполняются последовательно, занимая малые кванты процессорного времени.
Процессы и потоки
В различных источниках информации можно найти много разных определений процессов и потоков. Такой разброс определений обусловлен, во-первых, эволюцией операционных систем, которая приводила к изменению понятий о процессах и потоках, во-вторых, различием точек зрения, с которых рассматриваются эти понятия.
В рамках данной серии статей предлагаю придерживаться следующих определений...
С точки зрения пользователя:
Процесс – экземпляр программы во время выполнения;
Потоки – ветви кода, выполняющиеся «параллельно», то есть без предписанного порядка во времени.
С точки зрения операционной системы:
Процесс – это абстракция, реализованная на уровне операционной системы. Процесс был придуман для организации всех данных, необходимых для работы программы.
Процесс – это просто контейнер, в котором находятся ресурсы программы:
- адресное пространство;
- потоки;
- открытые файлы;
- дочерние процессы;
- и т.д.;
Поток – это абстракция, реализованная на уровне операционной системы. Поток был придуман для контроля выполнения кода программы.
Поток – это просто контейнер, в котором находятся:
- счётчик команд;
- регистры;
- стек.
Поток легче, чем процесс, и создание потока стоит дешевле. Потоки используют адресное пространство процесса, которому они принадлежат, поэтому потоки внутри одного процесса могут обмениваться данными и взаимодействовать с другими потоками.
Почему нужна поддержка множества потоков внутри одного процесса?
В случае, когда одна программа выполняет множество задач, поддержка множества потоков внутри одного процесса позволяет:
- разделить ответственность за разные задачи между разными потоками;
- повысить быстродействие.
Кроме того, часто задачам необходимо обмениваться данными, использовать общие данные или результаты других задач. Такую возможность предоставляют потоки внутри процесса, так как они используют адресное пространство процесса, которому принадлежат. Конечно можно было бы создать под разные задачи дополнительные процессы, но:
- у процесса будет отдельное адресное пространство и данные, что затруднит взаимодействие частей программы;
- создание и уничтожение процесса дороже, чем создание потока.
Отличие процесса от потока
Процесс рассматривается ОС, как заявка на все виды ресурсов (память, файлы и пр.), кроме одного – процессорного времени. Поток – это заявка на процессорное время. Процесс – это всего лишь способ сгруппировать взаимосвязанные данные и ресурсы, а потоки – это единицы выполнения (unit of execution), которые выполняются на процессоре.
Планирование, состояния потоков, приоритеты
Выбор текущего потока из нескольких активных потоков, пытающихся получить доступ к процессору, называется планированием. Процедура планирования обычно связана с весьма затратной процедурой диспетчеризации – переключением процессора на новый поток, поэтому планировщик должен заботиться об эффективном использовании процессора.
Поток может находиться в одном из трёх состояний:
- выполняемый (executing) – поток, который выполняется в текущий момент на процессоре;
- готовый (runnable) – поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков;
- ожидающий (waiting) – работа потока заблокирована в ожидании блокирующей операции.
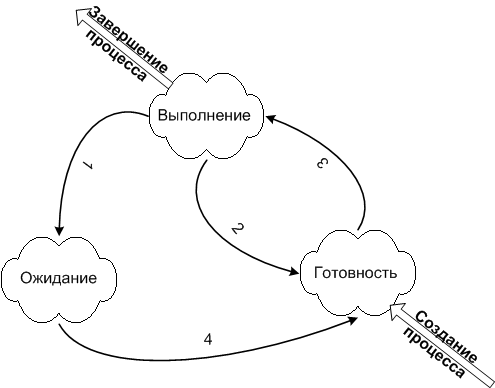
В реальных задачах важность работы разных потоков может сильно различаться. Для контроля этого процесса был придуман приоритет работы. У каждого потока есть такое числовое значение приоритета. Если есть несколько спящих потоков, которые нужно запустить, то ОС сначала запустит поток с более высоким приоритетом. ОС управляет потоками так, как посчитает нужным. Потоки с низким приоритетом не будут простаивать, просто они будут получать меньше времени, чем другие, но выполняться всё равно будут. Потоки с одинаковыми приоритетами запускаются в порядке очереди. Приоритет потока может меняться в процессе выполнения. Например, после завершения операции ввода-вывода могут увеличивать приоритет потока, чтобы дать ему возможность быстрее начать выполнение и, может быть, вновь инициировать операцию ввода-вывода. Таким способом система поощряет интерактивные потоки и поддерживает занятость устройств ввода-вывода.
Потоки могут быть созданы не только в режиме ядра, но и в режиме пользователя, в зависимости от того, какой планировщик потоков используется:
- Центральный планировщик ОС режима ядра, который распределяет время между любым потоком в системе.
- Планировщик библиотеки потоков. У библиотеки потоков режима пользователя может быть свой планировщик, который распределяет время между потоками различных процессов режима пользователя.
- Планировщик потоков процесса. К примеру свой Thread Manager есть у каждого процесса Mac OS X, написанного с использованием библиотеки Carbon.
Системные вызовы, режимы доступа
Системный вызов – это вызов функции ядра, из приложения пользователя.
Чтобы защитить жизненно важные системные данные от доступа и (или) внесения изменений со стороны пользовательских приложений, в WIndows и Linux используются два процессорных режима доступа (даже если процессор поддерживает более двух режимов): пользовательский режим и режим ядра.
Код пользовательского приложения запускается в пользовательском режиме, а код операционной системы (например, системные службы и драйверы устройств) запускается в режиме ядра. Режим ядра – такой режим работы процессора, в котором предоставляется доступ ко всей системной памяти и ко всем инструкциям центрального процессора. Предоставляя программному обеспечению операционной системы более высокий уровень привилегий, нежели прикладному программному обеспечению, процессор гарантирует, что приложения с неправильным поведением не смогут в целом нарушить стабильность работы системы.
Также следует отметить, что в случае выполнения системного вызова потоком и перехода из режима пользователя, в режим ядра, происходит смена стека потока на стек ядра. При переключении выполнения потока одного процесса, на поток другого, ОС обновляет некоторые регистры процессора, которые ответственны за механизмы виртуальной памяти (например CR3), так как разные процессы имеют разное виртуальное адресное пространство. Здесь я специально не затрагиваю аспекты относительно режима ядра, так как подобные вещи специфичны для отдельно взятой ОС.
Старайтесь не злоупотреблять средствами синхронизации, которые требуют системных вызовов ядра (например мьютексы). Переключение в режим ядра – дорогостоящая операция!
Задачи и проблемы многопоточности
Какие задачи решает многопоточная система?
К достоинствам многопоточной реализации той или иной системы перед однопоточной можно отнести следующее:
- Упрощение программы в некоторых случаях, за счёт вынесения механизмов чередования выполнения различных слабо взаимосвязанных подзадач, требующих одновременного выполнения, в отдельную подсистему многопоточности.
- Повышение производительности процесса за счёт распараллеливания процессорных вычислений и операций ввода-вывода.
К достоинствам многопоточной реализации той или иной системы перед многопроцессной можно отнести следующее:
- Упрощение программы (взаимодействия её параллельных частей) в некоторых случаях за счёт использования общего адресного пространства.
- Меньшие относительно процесса временные затраты на создание потока.
Распараллеливать работу приложения бывает удобно в самых разных ситуациях. Вот несколько примеров:
- Многопоточность широко используется в приложениях с пользовательским интерфейсом. В этом случае за работу интерфейса отвечает один поток, а какие-либо вычисления выполняются в других потоках. Это позволяет пользовательскому интерфейсу не подвисать, когда приложение занято другими вычислениями.
- Многие алгоритмы легко разбиваются на независимые подзадачи, которые можно выполнять в разных потоках для повышения производительности. Например, при фильтрации изображения разные потоки могут заниматься фильтрацией разных частей изображения.
- Если некоторые части приложения вынуждены ждать ответа от сервера/пользователя/устройства, то эти операции можно выделить в отдельный поток, чтобы в основном потоке можно было продолжать работу, пока другой поток ждёт ответа.
- и т.д.
Кроме того, многопоточную систему можно реализовать с возможностью масштабирования производительности. Например, при распараллеливании алгоритма количество создаваемых потоков может зависеть от количества процессорных ядер. Это позволит ускорять работу программы в определённых пределах, улучшая железо и не изменяя код.
Какие проблемы несёт реализация многопоточных приложений?
Когда потоки должны взаимодействовать друг с другом или работать с общими данными, могут возникать проблемы. Часто проблемы многопоточности иллюстрируются на следующих задачах:
- задача об обедающих философах;
- проблема спящего парикмахера;
- задача о курильщиках;
- задача о читателях-писателях;
- другие задачи.
Рассмотрим некоторые проблемы синхронизации.
Состояние гонки (race condition)
Состояние гонки – ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода.
Состояние гонки – «плавающая» ошибка (гейзенбаг), проявляющаяся в случайные моменты времени и «пропадающая» при попытке её локализовать.
Рассмотрим пример.
Допустим, каждый из двух потоков должен увеличить значение глобальной переменной 1. В идеальной ситуации последовательность операций должна быть следующая:
| Поток 1 | Поток 2 | Целочисленное значение | |
|---|---|---|---|
| 0 | |||
| прочитать значение | ← | 0 | |
| увеличить значение | 0 | ||
| записать обратно | → | 1 | |
| прочитать значение | ← | 1 | |
| увеличить значение | 1 | ||
| записать обратно | → | 2 |
В результате мы получаем значение 2, как и ожидали. Однако, если два потока работают одновременно, и их работа не синхронизируется, результат операции может быть неправильным. Возможна следующая последовательность операций:
| Поток 1 | Поток 2 | Целочисленное значение | |
|---|---|---|---|
| 0 | |||
| прочитать значение | ← | 0 | |
| прочитать значение | ← | 0 | |
| увеличить значение | 0 | ||
| увеличить значение | 0 | ||
| записать обратно | → | 1 | |
| записать обратно | → | 1 |
В этом случае результат будет равен 1, хотя ожидалось значение 2.
Код на C++, приводящий к состоянию гонки:
#include <iostream>
#include <thread>
int main()
{
unsigned long long g_count = 0;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
В данном примере решить проблему можно либо использованием атомарных операций вместо нескольких инструкций чтение-изменение-запись, либо ограничивая доступ потоков к переменной так, чтобы в один момент времени только один поток мог изменять переменную.
Использование атомарных операций:
#include <iostream>
#include <thread>
#include <atomic>
int main()
{
std::atomic<unsigned long long> g_count { 0 };
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
Подробнее про atomic:
Ограничение доступа к переменной так, чтобы только один поток в один момент времени мог изменять переменную:
int main()
{
unsigned long long g_count = 0;
std::mutex g_count_mutex;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
В этом примере поток перед тем как изменить переменную захватывает mutex (устанавливает флаг о том, что переменная занята), а другой поток, пытаясь захватить тот же mutex в это же время, обнаруживает, что первый поток уже работает с переменной, и дожидается её освобождения.
Подробнее про mutex:
Используя mutex в примере выше, мы синхронизируем работу потоков. Mutex является примитивом синхронизации.
Примитивы синхронизации – механизмы, позволяющие реализовать взаимодействие потоков, например, единовременный доступ только одного потока к критической области.
Примитивы синхронизации преследуют различные задачи:
- Взаимное исключение потоков – примитивы синхронизации гарантируют то, что единовременно с критической областью будет работать только один поток.
- Синхронизация потоков – примитивы синхронизации помогают отслеживать наступление тех или иных конкретных событий, то есть поток не будет работать, пока не наступило какое-то событие. Другой поток в таком случае должен гарантировать наступление данного события.
Однако если взаимоотношения между потоками более сложные, то неаккуратные блокировки потоков могут приводить к новой проблеме – взаимным блокировкам (deadlock).
Взаимная блокировка (deadlock)
Deadlock – ситуация, при которой несколько потоков находятся в состоянии ожидания ресурсов, занятых друг другом, и ни один из них не может продолжать выполнение.
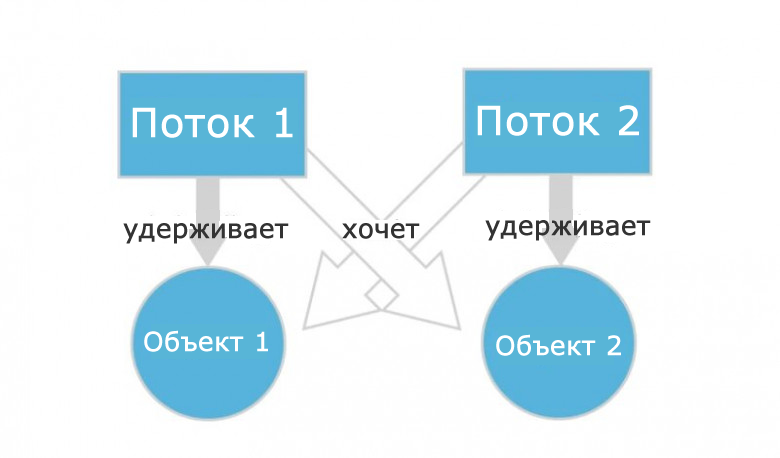
Представим, что поток 1 работает с каким-то объектом 1, а поток 2 работает с объектом 2. При этом программа написана так:
- Поток 1 перестанет работать с объектом 1 и переключится на объект 2, как только поток 2 перестанет работать с объектом 2 и переключится на объект 1.
- Поток 2 перестанет работать с объектом 2 и переключится на объект 1, как только поток 1 перестанет работать с объектом 1 и переключится на объект 2.
Даже не обладая глубокими знаниями в многопоточности, легко понять, что ничего из этого не получится. Потоки никогда не поменяются местами и будут ждать друг друга вечно. Ошибка кажется очевидной, но на самом деле это не так. Допустить ее в программе можно запросто.
Кстати, на Quora есть отличные примеры из реальной жизни, объясняющие что такое deadlock.
Пример возникновения взаимной блокировки в программе на C++:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m1);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Менее наглядный, но более жизненный пример можно посмотреть тут.
Классический способ борьбы с взаимными блокировками состоит в том, чтобы захватывать несколько мьютексов всегда в одинаковом порядке.
Более строго, это значит, что между блокировками устанавливается отношение сравнения и вводится правило о запрете захвата «большей» блокировки в состоянии, когда уже захвачена «меньшая». Таким образом, если процессу нужно несколько блокировок, ему нужно всегда начинать с самой «большой» – предварительно освободив все захваченные «меньшие», если такие есть – и затем в нисходящем порядке. Это может привести к лишним действиям (если «меньшая» блокировка нужна и уже захвачена, она освобождается только чтобы тут же быть захваченной снова), зато гарантированно решает проблему.
С учётом этого пример принимает следующий вид:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
В нашем простом примере легко было вручную задать верный порядок блокировки мьютексов, однако, это не всегда так легко. Например, в ситуации, когда два мьютекса передаются в функцию по ссылке и блокируются ею, порядок блокировки будет зависеть от порядка переданных аргументов. Поэтому для блокировки мьютексов одинаковом порядке стандартная библиотека предоставляет функцию std::lock (аналог std::mutex::lock()) и класс std::scoped_lock (аналог std::lock_guard).
std::scoped_lock – это улучшенная версия std::lock_guard, конструктор которого блокирует произвольное количество мьютексов в фиксированном порядке (как и std::lock). В новом коде следует использовать std::scoped_lock, std::lock_guard остался в языке для обратной совместимости. Пример:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Аналогичный код с std::lock и std::lock_guard выглядел бы следующим образом:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Если требуется больше гибкости, например, при использовании condition variables, можно использовать std::unique_lock:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Подробнее про unique_lock и lock_guard.
Другие проблемы
Кроме описанных выше проблем, иногда можно столкнуться с проблемой голодания потоков и с проблемой livelock.
Голодание потоков – это ситуация, в которой поток не может получить доступ к общим ресурсам, потому что на эти ресурсы всегда претендуют какие-то другие потоки, которым отдаётся предпочтение.
Поток часто действует в ответ на действие другого потока. Если действие другого потока также является ответом на действие первого потока, то может возникнуть livelock. Потоки не блокируются – они просто слишком заняты, реагируя на действия друг друга, чтобы возобновить работу.