Глава 14. HTTP веб-сервисы
Содержание главы
Погружение
С философской точки зрения я могу описать веб-сервисы HTTP в нескольких словах: обмен данными с удаленными серверами, использующий только операции HTTP. Если вы хотите получить данные с сервера, используйте HTTP GET. Если вы хотите отправить новые данные на сервер, используйте HTTP POST. API некоторых более продвинутых HTTP веб-сервисов также позволяют создавать, изменять и удалять данные, используя HTTP PUT и HTTP DELETE. Вот и всё. Нет реестров, нет конвертов, нет оболочек, нет туннелирования. «Глаголы», встроенные в протокол HTTP (GET, POST, PUT и DELETE) соответствуют операциям уровня приложения, выполняющим извлечение, создание, изменение и удаление данных.
Основным преимуществом этого подхода является простота, и его простота оказалась популярной. Данные (обычно XML или JSON) могут создаваться и храниться статически, или генерироваться динамически скриптом на стороне сервера, и все основные языки программирования (включая, конечно, Python!) включают в себя HTTP библиотеку для их загрузки. Отладка также проста; поскольку каждый ресурс в HTTP веб-сервисе имеет уникальный адрес (в виде URL), вы можете загрузить его в веб-браузере и увидеть необработанные данные.
Примеры HTTP веб-сервисов:
- Google Data API позволяет вам взаимодействовать с широким спектром сервисов Google, включая Blogger и YouTube;
- Сервисы Flickr позволяют загружать и скачивать фотографии с Flickr;
- Twitter API позволяет публиковать обновления в Twitter;
- ... и многое другое
Python 3 поставляется с двумя разными библиотеками для взаимодействия с HTTP веб-сервисами:
http.client– это низкоуровневая библиотека, которая реализует RFC 2616, протокол HTTP.urllib.request– это уровень абстракции, построенный поверхhttp.client. Он предоставляет стандартный API для доступа к HTTP и FTP серверам, автоматически выполняет перенаправления HTTP и обрабатывает некоторые распространенные формы HTTP аутентификации.
Так какую из них использовать? Никакую. Вместо этого вы должны использовать httplib2, стороннюю библиотеку с открытым исходным кодом, которая реализует HTTP более полно, чем http.client, и при этом обеспечивает лучшую абстракцию, чем urllib.request.
Чтобы понять, почему httplib2 – это правильный выбор, сначала нужно понять HTTP.
14.2 Функции HTTP
Есть пять важных функций, которые должны поддерживать все HTTP-клиенты.
14.2.1 Кеширование
Самая важная вещь, которую нужно понимать в любом веб-сервисе, это то, что доступ к сети невероятно дорог. Под «дорого» я не имею в виду «доллары и центы» (хотя пропускная способность не бесплатна). Я имею в виду, что требуется очень много времени, чтобы открыть соединение, отправить запрос и получить ответ с удаленного сервера. Даже на самом быстром широкополосном соединении задержка (время, необходимое для отправки запроса и начала получения данных в ответе) может быть выше, чем вы ожидали. Маршрутизатор работает неправильно, пакет отбрасывается, промежуточный прокси-сервер подвергается атаке – в общедоступном Интернете никогда не бывает скучно, и вы ничего не можете с этим поделать.
Cache-Control: max-ageозначает, «не надоедай мне до следующей недели».
HTTP разработан с учетом кеширования. Существует целый класс устройств (называемых «кеширующими прокси»), единственная задача которых – сидеть между вами и остальным миром и сводить к минимуму доступ к сети. Ваша компания или провайдер почти наверняка поддерживают кеширующие прокси-серверы, даже если вы о них не знаете. Они работают, потому что кеширование встроено в протокол HTTP.
Вот конкретный пример того, как работает кеширование. Вы посещаете diveintomark.org в вашем браузере. Эта страница содержит фоновое изображение wearehugh.com/m.jpg. Когда ваш браузер загружает это изображение, сервер включает следующие заголовки HTTP:
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
Заголовки Cache-Control и Expires сообщают вашему браузеру (и любым кеширующим прокси-серверам между вами и сервером), что это изображение может кешироваться на срок до года. Год! И если в следующем году вы посетите другую страницу, на которой также есть ссылка на это изображение, ваш браузер загрузит изображение из своего кеша без какой-либо сетевой активности.
Но подождите. Допустим, ваш браузер по какой-то причине удалит изображение из локального кеша. Возможно, из-за заканчивающегося места на диске; возможно, вы вручную очистили кеш. Без разницы. Но HTTP заголовки говорят, что эти данные могут быть кешированы публичными прокси-серверами. (Технически, важно то, что заголовки не говорят; заголовок Cache-Control не имеет ключевого слова private, поэтому эти данные по умолчанию кешируются.) Кеширующие прокси разработаны так, чтобы иметь тонны дискового пространства, вероятно, намного больше, чем выделено вашему локальном браузеру.
Если ваша компания или провайдер поддерживают кеширующий прокси-сервер, этот прокси-сервер всё еще может кешировать изображение. При повторном посещении diveintomark.org ваш браузер будет искать изображение в своем локальном кеше, но не найдет его, поэтому он отправит сетевой запрос на загрузку с удаленного сервера. Но если кеширующий прокси-сервер всё еще имеет копию этого изображения, он будет перехватывать этот запрос и выдавать изображение из своего кеша. Это означает, что ваш запрос никогда не достигнет удаленного сервера; на самом деле, он никогда не покинет сеть вашей компании. Это ускоряет загрузку (меньше сетевых скачков) и экономит деньги вашей компании (меньше данных загружается из внешнего мира).
HTTP кеширование работает только тогда, когда все делают свое дело. С одной стороны, серверы должны отправлять правильные заголовки в своем ответе. С другой стороны, клиенты должны понимать и учитывать эти заголовки, прежде чем запрашивать одни и те же данные дважды. Прокси в середине не панацея; они могут быть настолько умными, насколько им это позволяют серверы и клиенты.
HTTP библиотеки Python не поддерживают кеширование, а httplib2 поддерживает.
14.2.2 Проверка Last-Modified (времени последнего изменения)
Некоторые данные никогда не меняются, в то время как другие меняются постоянно. Между ними существует огромное поле данных, которые могли бы измениться, но не изменились. Фид CNN.com обновляется каждые несколько минут, но фид моего блога может не меняться днями или неделями. В последнем случае я не хочу просить клиентов кешировать мой фид на недели, потому что тогда, когда я действительно опубликую что-то, люди могут не прочитать это неделями (потому что они учитывают мои заголовки кеширования, которые говорят: «Не проверяйте этот канал в течение нескольких недель»). С другой стороны, я не хочу, чтобы клиенты загружали весь мой фид раз в час, если он не изменился!
304: Not Modifiedозначает, «день другой, дерьмо всё то же».
У HTTP для этого тоже есть решение. Когда вы запрашиваете данные в первый раз, сервер может вернуть заголовок Last-Modified. Это именно то, на что это похоже: дата, когда данные были изменены. Фоновое изображение, на которое ссылается diveintomark.org, содержит заголовок Last-Modified.
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
Когда вы запрашиваете те же данные во второй (или третий, или четвертый) раз, со своим запросом вы можете отправить заголовок If-Modified-Since с датой, которую вы получили с сервера в последний раз. Если данные с тех пор изменились, то сервер предоставит вам новые данные с кодом состояния 200. Но если с тех пор данные не изменились, сервер отправляет обратно специальный код состояния HTTP 304, что означает, что «эти данные не изменились с момента последнего запроса». Вы можете проверить это в командной строке с помощью curl:
you@localhost:~$ curl -I -H "If-Modified-Since: Fri, 22 Aug 2008 04:28:16 GMT" http://wearehugh.com/m.jpg
HTTP/1.1 304 Not Modified
Date: Sun, 31 May 2009 18:04:39 GMT
Server: Apache
Connection: close
ETag: "3075-ddc8d800"
Expires: Mon, 31 May 2010 18:04:39 GMT
Cache-Control: max-age=31536000, public
Почему это является улучшением? Потому что, когда сервер отправляет 304, он не отправляет данные повторно. Всё, что вы получаете, это код состояния. Даже после того, как срок действия вашей кешированной копии истек, проверка времени последнего изменения гарантирует, что вы не загрузите одни и те же данные дважды, если они не изменились. (В качестве дополнительного бонуса этот ответ 304 также включает в себя заголовки кеширования. Прокси-серверы сохранят копию данных даже после официального «истечения срока действия» в надежде, что данные на самом деле не изменились, и на следующий запрос сервер ответит кодом состояния 304 и обновленной информацией кеширования.)
HTTP библиотеки Python не поддерживают проверку даты последнего изменения, а httplib2 поддерживает.
14.2.3 Проверка ETag
ETag – это альтернативный способ выполнить то же самое, что и проверка времени последнего изменения. С помощью Etag сервер вместе с запрашиваемыми вами данными отправляет хеш-код в заголовке ETag. (Точно, как этот хеш определяется, полностью зависит от сервера. Единственное требование – чтобы он изменялся при изменении данных.) То фоновое изображение, на которое ссылается diveintomark.org, имеет заголовок ETag.
HTTP/1.1 200 OK
Date: Sun, 31 May 2009 17:14:04 GMT
Server: Apache
Last-Modified: Fri, 22 Aug 2008 04:28:16 GMT
ETag: "3075-ddc8d800"
Accept-Ranges: bytes
Content-Length: 12405
Cache-Control: max-age=31536000, public
Expires: Mon, 31 May 2010 17:14:04 GMT
Connection: close
Content-Type: image/jpeg
ETag означает «нет ничего нового под солнцем».
Во второй раз, когда вы запрашиваете те же данные, вы включаете хеш ETag в заголовок If-None-Match вашего запроса. Если данные не изменились, сервер отправит вам обратно код состояния 304. Как и при проверке времени последнего изменения, сервер отправляет обратно только код состояния 304; он не отправляет вам те же данные во второй раз. Включив хеш ETag во второй запрос, вы сообщаете серверу, что нет необходимости повторно отправлять те же данные, если они всё еще соответствуют этому хешу, поскольку у вас всё еще есть данные, полученные при последнем запросе.
И снова с curl:
you@localhost:~$ curl -I -H "If-None-Match: \"3075-ddc8d800\"" http://wearehugh.com/m.jpg ①
HTTP/1.1 304 Not Modified
Date: Sun, 31 May 2009 18:04:39 GMT
Server: Apache
Connection: close
ETag: "3075-ddc8d800"
Expires: Mon, 31 May 2010 18:04:39 GMT
Cache-Control: max-age=31536000, public
- Строка 1. ETag обычно заключен в кавычки, но кавычки являются частью значения. Это означает, что вам нужно в заголовке
If-None-Matchотправить кавычки обратно на сервер.
HTTP библиотеки Python не поддерживают ETag, а httplib2 поддерживает.
14.2.4 Сжатие
Когда мы говорим об HTTP веб-сервисах, мы почти всегда говорим о перемещении по сети текстовых данных назад и вперед. Может быть, это XML, может, это JSON, а может, просто текст. Независимо от формата текст хорошо сжимается. Пример с фидом в главе XML весит без сжатия 3070 байт, но после gzip сжатия он будет весить 941 байт. Это всего лишь 30% от исходного размера!
HTTP поддерживает несколько алгоритмов сжатия. Двумя наиболее распространенными являются gzip и deflate. Когда вы запрашиваете ресурс через HTTP, вы можете попросить сервер отправить его в сжатом формате. Для этого включите в запрос заголовок Accept-encoding, в котором перечислены поддерживаемые вами алгоритмы сжатия. Если сервер поддерживает какой-либо из этих алгоритмов, он отправит вам обратно сжатые данные (с заголовком Content-encoding, который сообщит вам, какой алгоритм он использовал). И тогда вам необходимо будет распаковать данные.
Важный совет для разработчиков на стороне сервера: убедитесь, что сжатая версия ресурса имеет Etag, отличающийся от несжатой версии. В противном случае кеширующие прокси могут запутаться и предоставить сжатую версию клиентам, которые не смогут ее обработать. Для получения более подробной информации по этому вопросу прочитайте обсуждение бага 39727 Apache.
HTTP библиотеки Python не поддерживают сжатие, а httplib2 поддерживает.
14.2.5 Перенаправление
Крутые URI адреса не меняются, но многие URI совсем не круты. Веб-сайты реорганизуются, страницы перемещаются по новым адресам. Даже веб-сервисы могут реорганизоваться. Организованный фид на http://example.com/index.xml может быть перемещен на http://example.com/xml/atom.xml. Или может быть перемещен весь домен из-за расширения и реорганизации организации; http://www.example.com/index.xml становится http://server-farm-1.example.com/index.xml.
Locationозначает, «смотри туда!»
Каждый раз, когда вы запрашиваете какой-либо ресурс с HTTP сервера, сервер включает в свой ответ код состояния. Код состояния 200 означает «всё нормально, вот страница, которую вы просили». Код состояния 404 означает, «страница не найдена» (вероятно, вы встречали ошибки 404 при просмотре веб-страниц). Трехсотые коды состояния указывают на некоторую форму перенаправления.
В HTTP есть несколько разных способов обозначить перемещение ресурса. Двумя наиболее распространенными методами являются коды состояния 302 и 301. Код состояния 302 – это временное перенаправление; это означает, «извините, что временно переехал сюда» (и затем дает временный адрес в заголовке Location). Код состояния 301 – постоянное перенаправление; это означает, «к сожалению, это было перемещено навсегда» (и затем дает новый адрес в заголовке Location). Если вы получаете код состояния 302 и новый адрес, спецификация HTTP говорит, что вы должны использовать новый адрес, чтобы получить то, что вы просили, но в следующий раз, когда вы захотите получить доступ к тому же ресурсу, вам следует повторить попытку со старым адресом. Но если вы получите код состояния 301 и новый адрес, с этого момента вы должны использовать новый адрес.
Модуль urllib.request, когда получает соответствующий код состояния от HTTP сервера, автоматически «следует» перенаправлению, но не сообщает об этом. В конечном итоге вы получите запрашиваемые данные, но никогда не узнаете, что базовая библиотека «услужливо» выполнила для вас перенаправление. Таким образом, вы продолжите стучать по старому адресу и каждый раз будете перенаправляться на новый адрес, и каждый раз модуль urllib.request будет «услужливо» следовать за перенаправлением. Другими словами, он обрабатывает постоянные перенаправления так же, как временные перенаправления. Это означает два запроса вместо одного, что плохо и для сервера, и для вас.
httplib2 обрабатывает постоянные перенаправления за вас. Он не только сообщит вам, что произошел постоянный редирект, но и будет отслеживать их локально и автоматически переписывать перенаправленные URL адреса, прежде чем запрашивать их.
14.3 Как не получать данные по HTTP
Допустим, вы хотите загрузить ресурс через HTTP, например, фид Atom. Будучи фидом, вы не просто загрузите его один раз; вы собираетесь загружать это снова и снова (большинство RSS-ридеров проверяют наличие изменений раз в час). Давайте сначала сделаем это «быстро и грязно», а затем посмотрим, как можно это улучшить.
>>> import urllib.request
>>> a_url = 'http://diveintopython3.org/examples/feed.xml'
>>> data = urllib.request.urlopen(a_url).read() ①
>>> type(data) ②
<class 'bytes'>
>>> print(data)
<?xml version='1.0' encoding='utf-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into mark</title>
<subtitle>currently between addictions</subtitle>
<id>tag:diveintomark.org,2001-07-29:/</id>
<updated>2009-03-27T21:56:07Z</updated>
<link rel='alternate' type='text/html' href='http://diveintomark.org/'/>
…
- Строка 3. Загрузка чего-либо через HTTP в Python невероятно проста; на самом деле, это одна строка. Модуль
urllib.requestсодержит удобную функциюurlopen(), которая принимает адрес нужной вам страницы и возвращает файлоподобный объект, который вы можете просто прочитать методомread(), чтобы получить всё содержимое страницы. Проще быть не может. - Строка 4. Метод
urlopen().read()всегда возвращает объектbytes, а не строку. Помните, байты – это байты; символы – это абстракция. HTTP серверы не работают с абстракциями. Если вы запрашиваете ресурс, вы получаете байты. Если вы хотите использовать его в виде строки, вам необходимо определить кодировку символов и явно преобразовать его в строку.
Что с этим не так? Для быстрой проверки во время тестирования или разработки в этом нет ничего плохого. Я так делаю всё время. Я хотел контент фида, и я получил контент фида. Тот же метод работает для любой веб-страницы. Но как только вы начинаете думать с точки зрения веб-сервиса, к которому вы хотите обращаться регулярно (например, запрашивать фид один раз в час), это становится неэффективно.
14.4 Что передается по сети?
Чтобы понять, почему это неэффективно и грубо, давайте включим функции отладки HTTP библиотеки Python и посмотрим, что отправляется «по проводам» (т.е. по сети).
>>> from http.client import HTTPConnection
>>> HTTPConnection.debuglevel = 1 ①
>>> from urllib.request import urlopen
>>> response = urlopen('http://diveintopython3.org/examples/feed.xml') ②
send: b'GET /examples/feed.xml HTTP/1.1 ③
Host: diveintopython3.org ④
Accept-Encoding: identity ⑤
User-Agent: Python-urllib/3.1' ⑥
Connection: close
reply: 'HTTP/1.1 200 OK'
…дальнейшая отладочная информация опущена…
- Строка 2. Как я упоминал в начале главы,
urllib.requestопирается на другую стандартную библиотеку Python,http.client. Обычно вам не нужно напрямую обращаться кhttp.client(модульurllib.requestимпортирует его автоматически). Но мы импортируем его здесь, чтобы можно было включить флаг отладки в классеHTTPConnection, которыйurllib.requestиспользует для подключения к HTTP серверу. - Строка 4. Теперь, когда установлен флаг отладки, информация об HTTP запросе и ответе распечатывается в режиме реального времени. Как вы можете видеть, когда мы запрашиваем фид Atom, модуль
urllib.requestотправляет на сервер пять строк. - Строка 5. В первой строке указывается используемый вами HTTP метод и путь к ресурсу (без имени домена).
- Строка 6. Во второй строке указывается имя домена, с которого мы запрашиваем этот фид.
- Строка 7. В третьей строке указываются алгоритмы сжатия, которые поддерживает клиент. Как я упоминал ранее,
urllib.requestпо умолчанию не поддерживает сжатие. - Строка 8. В четвертой строке указывается имя библиотеки, которая делает запрос. По умолчанию это Python-urllib плюс номер версии. И
urllib.request, иhttplib2поддерживают изменение агента пользователя, просто добавляя заголовокUser-Agentк запросу (который переопределит значение по умолчанию).
Теперь давайте посмотрим, что сервер отправил обратно в ответ.
# продолжение предыдущего примера
>>> print(response.headers.as_string()) ①
Date: Sun, 31 May 2009 19:23:06 GMT ②
Server: Apache
Last-Modified: Sun, 31 May 2009 06:39:55 GMT ③
ETag: "bfe-93d9c4c0" ④
Accept-Ranges: bytes
Content-Length: 3070 ⑤
Cache-Control: max-age=86400 ⑥
Expires: Mon, 01 Jun 2009 19:23:06 GMT
Vary: Accept-Encoding
Connection: close
Content-Type: application/xml
>>> data = response.read() ⑦
>>> len(data)
3070
- Строка 2. Ответ, возвращенный функцией
urllib.request.urlopen(), содержит все заголовки HTTP, отправленные сервером. Он также содержит методы для загрузки фактических данных; мы вернемся к этому через минуту. - Строка 3. Сервер сообщает вам, когда обработал ваш запрос.
- Строка 5. Этот ответ включает заголовок
Last-Modified. - Строка 6. Этот ответ включает заголовок
ETag. - Строка 8. Данные имеют длину 3070 байт. Обратите внимание, чего здесь нет: заголовка
Content-encoding. В вашем запросе говорилось, что вы принимаете только несжатые данные (Accept-encoding: identity), и, конечно же, этот ответ содержит несжатые данные. - Строка 9. Этот ответ включает в себя заголовки кеширования, в которых указано, что данный фид может кешироваться до 24 часов (86400 секунд).
- Строка 14. И, наконец, загрузим реальные данные, вызвав
response.read(). Как вы можете заметить из результата функцииlen(), всего было получено 3070 байт.
Как видите, этот код уже неэффективен: он запрашивает (и получает) несжатые данные. Я точно знаю, что этот сервер поддерживает сжатие GZIP, но в HTTP сжатие является необязательным. Мы не просили об этом, поэтому не получили его. Это означает, что мы получаем 3070 байт, когда могли бы получить 941.
Мы загружаем 3070 байт, когда мы могли бы загрузить только 941.
Но подождите, всё еще хуже! Чтобы увидеть, насколько неэффективен этот код, давайте запросим тот же фид во второй раз.
# продолжение предыдущего примера
>>> response2 = urlopen('http://diveintopython3.org/examples/feed.xml')
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
Accept-Encoding: identity
User-Agent: Python-urllib/3.1'
Connection: close
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
Заметили что-нибудь особенное в этом запросе? Он не изменился! Он точно такой же, как первый запрос. Никаких признаков заголовка If-Modified-Since. Никаких признаков заголовка If-None-Match. Никакой обработки заголовков кеширования. И всё еще без сжатия.
А что происходит, когда вы делаете одно и то же дважды? Вы получите тот же ответ. Дважды.
# продолжение предыдущего примера
>>> print(response2.headers.as_string()) ①
Date: Mon, 01 Jun 2009 03:58:00 GMT
Server: Apache
Last-Modified: Sun, 31 May 2009 22:51:11 GMT
ETag: "bfe-255ef5c0"
Accept-Ranges: bytes
Content-Length: 3070
Cache-Control: max-age=86400
Expires: Tue, 02 Jun 2009 03:58:00 GMT
Vary: Accept-Encoding
Connection: close
Content-Type: application/xml
>>> data2 = response2.read()
>>> len(data2) ②
3070
>>> data2 == data ③
True
- Строка 2. Сервер всё еще отправляет тот же массив «умных» заголовков:
Cache-ControlиExpires, чтобы разрешить кеширование,Last-ModifiedиETag, чтобы включить отслеживание «неизменения». Даже заголовокVary: Accept-Encodingнамекает на то, что сервер будет поддерживать сжатие, если вы только об этом попросите. Но мы не просили. - Строка 15. Еще раз, этот запрос возвращает все 3070 байт ...
- Строка 17. … те же самые 3070 байт, которые мы получили в прошлый раз.
HTTP предназначен для работы лучшей, чем эта. urllib говорит по-английски, как я говорю по-испански – достаточно, чтобы выжить в пробке, но недостаточно, чтобы вести разговор. HTTP – это разговор. Пришло время, перейти на библиотеку, которая свободно говорит по HTTP.
14.5 Введение в httplib2
Прежде чем вы сможете использовать httplib2, необходимо его установить. Посетите https://github.com/httplib2/httplib2 и загрузите последнюю версию. httplib2 доступен для Python 2.x и Python 3.x; убедитесь, что вы скачали версию для Python 3, названную как-то вроде httplib2-python3-0.5.0.zip.
Распакуйте архив, откройте окно терминала и перейдите во вновь созданный каталог httplib2. В Windows откройте меню «Пуск», выберите «Выполнить...», введите cmd.exe и нажмите клавишу ENTER.
c:\Users\pilgrim\Downloads> dir
Volume in drive C has no label.
Volume Serial Number is DED5-B4F8
Directory of c:\Users\pilgrim\Downloads
07/28/2009 12:36 PM <DIR> .
07/28/2009 12:36 PM <DIR> ..
07/28/2009 12:36 PM <DIR> httplib2-python3-0.5.0
07/28/2009 12:33 PM 18,997 httplib2-python3-0.5.0.zip
1 File(s) 18,997 bytes
3 Dir(s) 61,496,684,544 bytes free
c:\Users\pilgrim\Downloads> cd httplib2-python3-0.5.0
c:\Users\pilgrim\Downloads\httplib2-python3-0.5.0> c:\python31\python.exe setup.py install
running install
running build
running build_py
running install_lib
creating c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\iri2uri.py -> c:\python31\Lib\site-packages\httplib2
copying build\lib\httplib2\__init__.py -> c:\python31\Lib\site-packages\httplib2
byte-compiling c:\python31\Lib\site-packages\httplib2\iri2uri.py to iri2uri.pyc
byte-compiling c:\python31\Lib\site-packages\httplib2\__init__.py to __init__.pyc
running install_egg_info
Writing c:\python31\Lib\site-packages\httplib2-python3_0.5.0-py3.1.egg-info
В Mac OS X запустите приложение Terminal.app в папке /Applications/Utilities/. В Linux запустите приложение Terminal, которое обычно находится в меню «Приложения» в разделе «Стандартные» или «Система».
you@localhost:~/Desktop$ unzip httplib2-python3-0.5.0.zip
Archive: httplib2-python3-0.5.0.zip
inflating: httplib2-python3-0.5.0/README
inflating: httplib2-python3-0.5.0/setup.py
inflating: httplib2-python3-0.5.0/PKG-INFO
inflating: httplib2-python3-0.5.0/httplib2/__init__.py
inflating: httplib2-python3-0.5.0/httplib2/iri2uri.py
you@localhost:~/Desktop$ cd httplib2-python3-0.5.0/
you@localhost:~/Desktop/httplib2-python3-0.5.0$ sudo python3 setup.py install
running install
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.1
creating build/lib.linux-x86_64-3.1/httplib2
copying httplib2/iri2uri.py -> build/lib.linux-x86_64-3.1/httplib2
copying httplib2/__init__.py -> build/lib.linux-x86_64-3.1/httplib2
running install_lib
creating /usr/local/lib/python3.1/dist-packages/httplib2
copying build/lib.linux-x86_64-3.1/httplib2/iri2uri.py -> /usr/local/lib/python3.1/dist-packages/httplib2
copying build/lib.linux-x86_64-3.1/httplib2/__init__.py -> /usr/local/lib/python3.1/dist-packages/httplib2
byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/iri2uri.py to iri2uri.pyc
byte-compiling /usr/local/lib/python3.1/dist-packages/httplib2/__init__.py to __init__.pyc
running install_egg_info
Writing /usr/local/lib/python3.1/dist-packages/httplib2-python3_0.5.0.egg-info
Чтобы использовать httplib2, создайте экземпляр класса httplib2.Http.
>>> import httplib2
>>> h = httplib2.Http('.cache') ①
>>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ②
>>> response.status ③
200
>>> content[:52] ④
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content)
3070
- Строка 2. Основным интерфейсом для
httplib2является объектHttp. По причинам, которые вы увидите в следующем разделе, при создании объектаHttpвы всегда должны передавать имя каталога. Каталог не должен существовать;httplib2создаст его при необходимости. - Строка 3. Если у вас есть объект
Http, получение данных так же просто, как вызов методаrequest()с адресом нужных вам данных. Это выдаст HTTP запросGETдля этого URL. (Позже в этой главе вы узнаете, как выдавать другие HTTP запросы, например,POST.) - Строка 4. Метод
request()возвращает два значения. Первое – это объектhttplib2.Response, который содержит все HTTP заголовки, возвращаемые сервером. Например, код состояния 200 указывает, что запрос был успешным. - Строка 6. Переменная
contentсодержит фактические данные, которые были возвращены HTTP сервером. Данные возвращаются как объектbytes, а не как строка. Если вы хотите использовать его в виде строки, вам необходимо определить кодировку символов и преобразовать ее самостоятельно.
Вам, вероятно, будет нужен только один объект httplib2.Http. Для создания более одного объекта могут быть веские причины, но вы должны делать это только в том случае, если знаете, зачем они вам нужны. «Мне нужно запросить данные с двух разных URL адресов» не является веской причиной. Повторно используйте объект Http и просто вызовите метод request() дважды.
14.5.1 Короткое отступление, объясняющее, почему httplib2 возвращает байты вместо строк
Байты. Строки. Это боль. Почему httplib2 «просто» не может выполнить преобразование для вас? Ну, это сложно, потому что правила определения кодировки символов зависят от того, какой ресурс вы запрашиваете. Как httplib2 может узнать, какой ресурс вы запрашиваете? Обычно он указывается в HTTP заголовке Content-Type, но это необязательная функция HTTP, и не все HTTP серверы включают ее. Если этот заголовок не включен в HTTP ответ, клиенту остается только угадать (это обычно называют «анализом контента» и никогда не бывает идеальным).
Если вы знаете, какой ресурс вы ожидаете (в данном случае это документ XML), возможно, вы могли бы просто передать возвращенный объект bytes в функцию xml.etree.ElementTree.parse(). Это будет работать до тех пор, пока XML документ содержит информацию о собственной кодировке символов, но это необязательная функция, и не все XML документы ее выполняют. Если XML документ не включает информацию о кодировке, клиент должен посмотреть на транспорт – то есть HTTP заголовок Content-Type, который может включать параметр charset.
Но всё еще хуже. Теперь информация о кодировке символов может находиться в двух местах: в самом документе XML и в HTTP заголовке Content-Type. Если информация есть в обоих местах, кто победит? Согласно RFC 3023 (клянусь, я не придумываю это), если тип медиа, указанный в HTTP заголовке Content-Type, – application/xml, application/xml-dtd, application/xml-external-parsed-entity или любой другой один из подтипов application/xml, такой как application/atom+xml или application/rss+xml или даже application/rdf+xml, тогда кодировка это:
- кодировка, указанная в параметре
charsetHTTP заголовкаContent-Type, или - кодировка, указанная в атрибуте
encodingобъявления XML в документе, или - UTF-8.
С другой стороны, если тип медиа, указанный в HTTP заголовке Content-Type, – это text/xml, text/xml-external-parsed-entity или подтип типа text/AnythingAtAll+xml, тогда атрибут encoding объявления XML в документе полностью игнорируется, а кодировка это:
- кодировка, указанная в параметре
charsetHTTP заголовкаContent-Type, или - us-ascii.
И это только для документов XML. Для HTML документов веб-браузеры создали такие византийские правила для анализа контента [PDF], что мы всё еще пытаемся понять их.
14.5.2 Как httplib2 обрабатывает кеширование
Помните, в предыдущем разделе я говорил, что всегда следует создавать объект httplib2.Http с именем каталога? Причина этого – кеширование.
# продолжение предыдущего примера
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml') ①
>>> response2.status ②
200
>>> content2[:52] ③
b"<?xml version='1.0' encoding='utf-8'?>\r\n<feed xmlns="
>>> len(content2)
3070
- Строка 2. Это не должно казаться странным. Это то же самое, что мы делали в прошлый раз, за исключением того, что теперь помещаем результат в две новые переменные.
- Строка 3. HTTP статус снова 200, как в прошлый раз.
- Строка 5. Загруженный контент такой же, как и в прошлый раз.
Итак... что в этом интересного? Закройте интерактивную оболочку Python и перезапустите ее с новым сеансом, и я покажу вам.
# НЕ продолжение предыдущего примера!
# Выйдите, пожалуйста, и интерактивной оболочки
# и запустите новую.
>>> import httplib2
>>> httplib2.debuglevel = 1 ①
>>> h = httplib2.Http('.cache') ②
>>> response, content = h.request('http://diveintopython3.org/examples/feed.xml') ③
>>> len(content) ④
3070
>>> response.status ⑤
200
>>> response.fromcache ⑥
True
- Строка 5. Давайте включим отладку и посмотрим, что передается по сети. Это эквивалент
httplib2включения отладки вhttp.client.httplib2напечатает все данные, отправляемые на сервер, и некоторую ключевую информацию, отправляемую обратно. - Строка 6. Создайте объект
httplib2.Httpс тем же именем каталога, что и раньше. - Строка 7. Запросите тот же URL адрес, что и раньше. Ничего не происходит. Точнее, ничего не отправляется на сервер, и ничего не возвращается с сервера. Нет абсолютно никакой сетевой активности вообще.
- Строка 8. Тем не менее, мы «получили» какие-то данные – на самом деле мы получили всё.
- Строка 10. Мы также «получили» код статуса HTTP, указывающий, что «запрос» был успешным.
- Строка 12. Вот в чем дело: этот «ответ» был сгенерирован из локального кеша
httplib2. Имя каталога, которое вы указали при создании объектаhttplib2.Http– этот каталог содержит кешhttplib2для всех операций, которые он когда-либо выполнял.
Что передается по сети? Абсолютно ничего.
Если вы хотите включить отладку httplib2, вам нужно установить константу уровня модуля (httplib2.debuglevel), а затем создать новый объект httplib2.Http. Если вы хотите отключить отладку, вам нужно изменить ту же самую константу уровня модуля, а затем создать новый объект httplib2.Http.
Ранее мы запрашивали данные по этому URL. Этот запрос был успешным (статус: 200). Этот ответ включал в себя не только данные фида, но также набор заголовков кеширования, которые сообщали всем, кто слушал, что они могут кешировать этот ресурс до 24 часов (Cache-Control: max-age = 86400, что в секундах равно 24 часам). httplib2 понимает и учитывает эти заголовки кеширования и сохраняет предыдущий ответ в каталоге .cache (который мы передали при создании объекта Http). Срок действия этого кеша еще не истек, поэтому во второй раз, когда мы запросили данные по этому URL адресу, httplib2 просто вернул кешированный результат, даже не обратившись к сети.
Я говорю «просто», но, очевидно, за этой простотой скрывается много сложностей. httplib2 обрабатывает кеширование HTTP автоматически и по умолчанию. Если по какой-то причине вам необходимо узнать, поступил ли ответ из кеша, вы можете проверить response.fromcache. В противном случае всё будет просто работать.
Теперь предположим, что у вас есть данные в кеше, но вы хотите обойти кеш и повторно запросить данные с удаленного сервера. Браузеры иногда делают так, если пользователь специально запрашивает это. Например, нажатие F5 обновляет текущую страницу, а нажатие Ctrl + F5 обходит кеш и повторно запрашивает текущую страницу с удаленного сервера. Вы можете подумать: «Я просто удалю данные из своего локального кеша, а затем запрошу их снова». Вы можете так сделать, но помните, что может быть вовлечено больше сторон, чем только вы и удаленный сервер. Как насчет промежуточных прокси-серверов? Они полностью находятся вне вашего контроля, и, возможно, они всё еще будут кешировать эти данные и с радостью вернут их вам, поскольку их кеш всё еще действителен.
Вместо того чтобы манипулировать локальным кешем и надеяться на лучшее, вы должны использовать функции HTTP, чтобы гарантировать, что ваш запрос действительно достигнет удаленного сервера.
# продолжение предыдущего примера
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed.xml',
... headers={'cache-control':'no-cache'}) ①
connect: (diveintopython3.org, 80) ②
send: b'GET /examples/feed.xml HTTP/1.1
Host: diveintopython3.org
user-agent: Python-httplib2/$Rev: 259 $
accept-encoding: deflate, gzip
cache-control: no-cache'
reply: 'HTTP/1.1 200 OK'
…further debugging information omitted…
>>> response2.status
200
>>> response2.fromcache ③
False
>>> print(dict(response2.items())) ④
{'status': '200',
'content-length': '3070',
'content-location': 'http://diveintopython3.org/examples/feed.xml',
'accept-ranges': 'bytes',
'expires': 'Wed, 03 Jun 2009 00:40:26 GMT',
'vary': 'Accept-Encoding',
'server': 'Apache',
'last-modified': 'Sun, 31 May 2009 22:51:11 GMT',
'connection': 'close',
'-content-encoding': 'gzip',
'etag': '"bfe-255ef5c0"',
'cache-control': 'max-age=86400',
'date': 'Tue, 02 Jun 2009 00:40:26 GMT',
'content-type': 'application/xml'}
- Строка 3.
httplib2позволяет к любому исходящему запросу добавлять произвольные HTTP заголовки. Чтобы обойти все кеши (не только ваш локальный дисковый кеш, но и любые кеширующие прокси-серверы между вами и удаленным сервером), добавьте заголовокno-cacheв словарьheaders. - Строка 4. Теперь мы видим, что
httplib2инициирует сетевой запрос.httplib2понимает и учитывает заголовки кеширования в обоих направлениях: и как часть входящего ответа, и как часть исходящего запроса. Он заметил, что вы добавили заголовокno-cache, поэтому он вообще обошел свой локальный кеш, и у него не было выбора, кроме как подключиться к сети и запросить данные. - Строка 14. Этот ответ не был сгенерирован из нашего локального кеша. Мы знаем это, конечно, потому что увидели отладочную информацию об исходящем запросе. Но приятно, что это можно проверить программно.
- Строка 16. Запрос выполнен успешно; мы снова загрузили с удаленного сервера весь фид. Конечно, сервер вместе с данными фида также отправил полный набор HTTP заголовков. Это включает в себя заголовки кеширования, которые
httplib2использует для обновления своего локального кеша, в надежде избежать доступа к сети при следующем запросе этого фида. Всё, что связано с HTTP кешированием, предназначено для максимального увеличения количества обращений к кешу и минимизации доступа к сети. Несмотря на то, что в этот раз вы обошли кеш, удаленный сервер был бы очень благодарен, если бы в следующий раз вы кешировали результат.
14.5.3 Как httplib2 обрабатывает заголовки Last-Modified и ETag
Заголовки кеширования Cache-Control и Expires называются индикаторами свежести. Они недвусмысленно сообщают кешам, что вы можете полностью избежать доступа к сети до истечения срока действия кеша. И это именно то поведение, которое мы видели в предыдущем разделе: учитывая индикатор свежести, httplib2 для обработки кешированных данных не генерировал ни одного байта сетевой активности (если, конечно, вы явно не обходите кеш).
Но как насчет случая, когда данные могли измениться, но не изменились? Для этого HTTP определяет заголовки Last-Modified и Etag. Эти заголовки называются валидаторами. Если локальный кеш больше не свеж, клиент может со следующим запросом отправить валидаторы, чтобы узнать, действительно ли изменились данные. Если данные не изменились, сервер отправляет обратно код состояния 304 и никаких данных. Таким образом, хотя и есть взаимодействие по сети, но в итоге вы загружаете меньше байтов.
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items())) ②
{'-content-encoding': 'gzip',
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '200',
'vary': 'Accept-Encoding,User-Agent'}
>>> len(content) ③
6657
- Строка 4. Вместо фида в этот раз мы будем загружать домашнюю страницу сайта, которая представляет собой HTML. Поскольку мы впервые запрашиваем эту страницу,
httplib2практически не с чем работать, и он вместе с запросом отправляет минимум заголовков. - Строка 11. Ответ содержит множество HTTP заголовков… но не содержит информации для кеширования. Однако он содержит заголовки
ETagиLast-Modified. - Строка 24. В то время, когда я создавал этот пример, эта страница весила 6657 байт. Возможно, с тех пор она изменилась, но не беспокойтесь об этом.
# продолжение предыдущего примера
>>> response, content = h.request('http://diveintopython3.org/') ①
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
if-none-match: "7f806d-1a01-9fb97900" ②
if-modified-since: Tue, 02 Jun 2009 02:51:48 GMT ③
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 304 Not Modified' ④
>>> response.fromcache ⑤
True
>>> response.status ⑥
200
>>> response.dict['status'] ⑦
'304'
>>> len(content) ⑧
6657
- Строка 2. Мы снова запрашиваем ту же страницу, с тем же объектом
Http(и тем же локальным кешем). - Строка 6.
httplib2отправляет валидаторETagобратно на сервер в заголовкеIf-None-Match. - Строка 7.
httplib2также отправляет валидаторLast-Modifiedобратно на сервер в заголовкеIf-Modified-Since. - Строка 10. Сервер посмотрел на эти валидаторы, посмотрел на запрошенную вами страницу и определил, что страница не изменилась со времени вашего последнего запроса, и поэтому отправляет обратно код состояния 304 и никаких данных.
- Строка 11. Возвращаемся к клиенту,
httplib2замечает код состояния 304 и загружает содержимое страницы из своего кеша. - Строка 13. Это может немного запутывать. На самом деле существует два кода состояния – 304 (возвращенный с сервера в этот раз, и который заставил
httplib2просмотреть его кеш), и 200 (возвращенный с сервера в последний раз и сохраненный в кешеhttplib2вместе с данными страницы).response.statusвозвращает статус из кеша. - Строка 15. Если вам нужен необработанный код состояния, который был возвращен с сервера, вы можете получить его, посмотрев в
response.dict, словарь фактических заголовков, возвращаемых с сервера. - Строка 17. Однако вы по-прежнему получаете данные в переменной
content. Как правило, вам не нужно знать, почему был получен ответ из кеша. (Вы можете даже не заботиться о том, что они выдаются из кеша, и это тоже нормально.httplib2достаточно умен, чтобы позволить вам действовать глупо.) К тому времени, когда методrequest()возвращается к вызывающей стороне,httplib2уже обновил свой кеш и вернул вам данные.
14.5.4 Как httplib2 обрабатывает сжатие
HTTP поддерживает несколько типов сжатия; два наиболее распространенных типа – это gzip и deflate. httplib2 поддерживает обоих.
>>> response, content = h.request('http://diveintopython3.org/')
connect: (diveintopython3.org, 80)
send: b'GET / HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip ①
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
>>> print(dict(response.items()))
{'-content-encoding': 'gzip', ②
'accept-ranges': 'bytes',
'connection': 'close',
'content-length': '6657',
'content-location': 'http://diveintopython3.org/',
'content-type': 'text/html',
'date': 'Tue, 02 Jun 2009 03:26:54 GMT',
'etag': '"7f806d-1a01-9fb97900"',
'last-modified': 'Tue, 02 Jun 2009 02:51:48 GMT',
'server': 'Apache',
'status': '304',
'vary': 'Accept-Encoding,User-Agent'}
- Строка 5. Каждый раз, когда
httplib2отправляет запрос, он включает заголовокAccept-Encoding, чтобы сообщить серверу, что он может обрабатывать сжатие либо deflate, либо gzip. - Строка 9. В данном случае сервер ответил полезной нагрузкой, сжатой gzip. Ко времени возврата из метода
request()httplib2уже распаковал тело ответа и поместил его в переменнуюcontent. Если вам интересно, был ли сжат ответ, вы можете проверитьresponse['-content-encoding']; или просто не беспокойтесь об этом.
14.5.5 Как httplib2 обрабатывает перенаправления
HTTP определяет два вида перенаправлений: временное и постоянное. Ничего особенного с временными перенаправлениями делать не нужно, кроме как следовать за ними, что httplib2 делает автоматически.
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> response, content = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
send: b'GET /examples/feed.xml HTTP/1.1 ④
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 200 OK'
- Строка 4. По этому URL адресу нет фида. Я настроил свой сервер для временного перенаправления на правильный адрес.
- Строка 6. Запрос.
- Строка 10. И ответ: 302 Found. Здесь не показано, но этот ответ также включает в себя заголовок
Location, который указывает на реальный URL. - Строка 11.
httplib2немедленно поворачивается и «следует» за перенаправлением, выполнив еще один запрос на URL, указанный в заголовкеLocation: http://diveintopython3.org/examples/feed.xml.
«Следование» за редиректом – это не более, чем показано в этом примере. httplib2 отправляет запрос на URL, который вы просили. Сервер возвращает ответ «Нет, нет, посмотрите туда». httplib2 отправляет еще один запрос на новый URL.
# продолжение предыдущего примера
>>> response ①
{'status': '200',
'content-length': '3070',
'content-location': 'http://diveintopython3.org/examples/feed.xml', ②
'accept-ranges': 'bytes',
'expires': 'Thu, 04 Jun 2009 02:21:41 GMT',
'vary': 'Accept-Encoding',
'server': 'Apache',
'last-modified': 'Wed, 03 Jun 2009 02:20:15 GMT',
'connection': 'close',
'-content-encoding': 'gzip', ③
'etag': '"bfe-4cbbf5c0"',
'cache-control': 'max-age=86400', ④
'date': 'Wed, 03 Jun 2009 02:21:41 GMT',
'content-type': 'application/xml'}
- Строка 2. Ответ
response, который мы получили от этого единственного вызова методаrequest(), является ответом с окончательного URL адреса. - Строка 5.
httplib2добавляет окончательный URL адрес в словарьresponseкакcontent-location. Это не заголовок, который пришел с сервера; это специфично дляhttplib2. - Строка 12. Ни с того ни с сего, этот фид сжат.
- Строка 14. И кешируется (это важно, как вы увидите через минуту).
Ответ response, который вы получите, даст вам информацию об окончательном URL. Что делать, если вам нужна дополнительная информация о промежуточных URL адресах, которые в конечном итоге перенаправляются на конечный URL адрес? httplib2 также позволяет вам ее получить.
# продолжение предыдущего примера
>>> response.previous ①
{'status': '302',
'content-length': '228',
'content-location': 'http://diveintopython3.org/examples/feed-302.xml',
'expires': 'Thu, 04 Jun 2009 02:21:41 GMT',
'server': 'Apache',
'connection': 'close',
'location': 'http://diveintopython3.org/examples/feed.xml',
'cache-control': 'max-age=86400',
'date': 'Wed, 03 Jun 2009 02:21:41 GMT',
'content-type': 'text/html; charset=iso-8859-1'}
>>> type(response) ②
<class 'httplib2.Response'>
>>> type(response.previous)
<class 'httplib2.Response'>
>>> response.previous.previous ③
>>>
- Строка 2. Атрибут
response.previousсодержит ссылку на предыдущий объект ответа, за которым следовалhttplib2, чтобы получить текущий объект ответа. - Строка 13. И
response, иresponse.previousявляются объектамиhttplib2.Response. - Строка 17. Это означает, что вы можете проверить
response.previous.previous, чтобы следовать цепочке перенаправления в обратном направлении еще дальше. (Сценарий: один URL перенаправляет на второй URL, который перенаправляет на третий URL. Это может произойти!) В этом случае мы уже достигли начала цепочки перенаправления, поэтому этот атрибут равенNone.
Что произойдет, если вы снова запросите тот же URL?
# продолжение предыдущего примера
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-302.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-302.xml HTTP/1.1 ②
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 302 Found' ③
>>> content2 == content ④
True
- Строка 2. Тот же URL, тот же объект
httplib2.Http(и, следовательно, тот же кеш). - Строка 4. Ответ 302 не был кеширован, поэтому
httplib2отправляет еще один запрос на тот же URL адрес. - Строка 8. Сервер снова отвечает 302. Но обратите внимание, что не произошло: не было второго запроса на окончательный URL, http://diveintopython3.org/examples/feed.xml. Этот ответ был кеширован (вспомните заголовок
Cache-Control, который мы видели в предыдущем примере). Как толькоhttplib2получил код 302 Found, перед отправкой другого запроса он проверил свой кеш. Кеш содержал свежую копию http://diveintopython3.org/examples/feed.xml, поэтому не было необходимости запрашивать его повторно. - Строка 9. Ко времени возврата метода
request()он прочитал данные фида из кеша и возвратил их. Конечно, это те же данные, которые вы получили в прошлый раз.
Другими словами, вам не нужно делать ничего особенного для временных перенаправлений. httplib2 будет следовать за ними автоматически, и тот факт, что один URL перенаправляет на другой, не имеет никакого отношения к поддержке httplib2 сжатия, кеширования, ETag или любых других функций HTTP.
Постоянные перенаправления так же просты.
# продолжение предыдущего примера
>>> response, content = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
connect: (diveintopython3.org, 80)
send: b'GET /examples/feed-301.xml HTTP/1.1
Host: diveintopython3.org
accept-encoding: deflate, gzip
user-agent: Python-httplib2/$Rev: 259 $'
reply: 'HTTP/1.1 301 Moved Permanently' ②
>>> response.fromcache ③
True
- Строка 2. Еще раз, этот URL на самом деле не существует. Я настроил свой сервер для выдачи постоянного перенаправления на http://diveintopython3.org/examples/feed.xml.
- Строка 8. И вот оно: код состояния 301. Но, опять же, обратите внимание, что не произошло: не было запроса на URL перенаправления. Почему? Потому что он уже кеширован локально.
- Строка 9.
httplib2«следовал» за перенаправлением прямо в кеш.
Но подождите! Есть еще кое-что!
# продолжение предыдущего примера
>>> response2, content2 = h.request('http://diveintopython3.org/examples/feed-301.xml') ①
>>> response2.fromcache ②
True
>>> content2 == content ③
True
- Строка 2. В этом заключается разница между временным и постоянным перенаправлениями: как только
httplib2следует за постоянным перенаправлением, все последующие запросы на этот URL адрес будут прозрачно переписаны на целевой URL адрес, не затрагивая сеть для исходного URL адреса. Помните, что отладка всё еще включена, а сетевой активности не видно. - Строка 3. Да, этот ответ был получен из локального кеша.
- Строка 5. Да, мы получили весь фид (из кеша).
HTTP. Он работает.
14.6 Помимо HTTP GET
Веб-сервисы HTTP не ограничиваются запросами GET. Что делать, если вы хотите создать что-то новое? Всякий раз, когда вы публикуете комментарий на форуме, обновляете свой блог, публикуете свой статус в сервисе микроблогов, таком как Twitter или Identi.ca, вы, вероятно, уже используете HTTP POST.
И Twitter, и Identi.ca для публикаций и обновлений вашего статуса длиной не более 140 символов предлагают простой API на основе HTTP. Давайте посмотрим на документацию API Identi.ca для обновления вашего статуса:
Identi.ca rest api Method: statuses/update
Обновляет статус аутентифицирующего пользователя. Требуется параметр status, указанный ниже. Запрос должен быть POST.
- URL
- https://identi.ca/api/statuses/update.format
- Форматы
- xml, json, rss, atom
- HTTP метод(ы)
- POST
- Требуется аутентификация
- Да
- Параметры
status. Обязательный. Текст вашего обновления статуса. URL кодирование необходимо.
Как это работает? Чтобы опубликовать новое сообщение на Identi.ca, вам нужно отправить HTTP запрос POST на адрес http://identi.ca/api/statuses/update.format. (Часть format не является частью URL адреса; вы заменяете его форматом данных, который сервер должен возвращать в ответ на ваш запрос. Поэтому, если вы хотите получить ответ в формате XML, вы должны отправить запрос в https://identi.ca/api/statuses/update.xml.) Запрос должен содержать параметр с именем status, который содержит текст вашего обновления статуса. И запрос должен быть аутентифицирован.
Аутентифицирован? Конечно. Чтобы обновить свой статус на Identi.ca, вам нужно доказать, кто вы есть. Identi.ca – это не вики; только вы можете обновить свой собственный статус. Для обеспечения безопасной, но простой в использовании аутентификации Identi.ca использует HTTP Basic Authentication (она же RFC 2617) поверх SSL. httplib2 поддерживает и SSL, и HTTP Basic Authentication, поэтому тут всё просто.
Запрос POST отличается от запроса GET, поскольку он включает в себя полезную нагрузку. Полезная нагрузка – это данные, которые вы хотите отправить на сервер. Единственный фрагмент данных, который требуется для этого метода API, – это status, и он должен быть URL кодирован (URL-encoded). Это очень простой формат сериализации, который принимает набор пар ключ-значение (то есть словарь) и преобразует его в строку.
>>> from urllib.parse import urlencode ①
>>> data = {'status': 'Test update from Python 3'} ②
>>> urlencode(data) ③
'status=Test+update+from+Python+3'
- Строка 1. Python поставляется с утилитой для url-кодирования словаря:
urllib.parse.urlencode(). - Строка 2. Это своего рода словарь, который ищет API Identi.ca. Он содержит один ключ,
status, значением которого является текст одного обновления статуса. - Строка 3. Вот как выглядит строка в кодировке URL. Это полезная нагрузка, которая будет отправлена «по сети» в нашем HTTP запросе
POSTна API сервер Identi.ca.
>>> from urllib.parse import urlencode
>>> import httplib2
>>> httplib2.debuglevel = 1
>>> h = httplib2.Http('.cache')
>>> data = {'status': 'Test update from Python 3'}
>>> h.add_credentials('diveintomark', 'MY_SECRET_PASSWORD', 'identi.ca') ①
>>> resp, content = h.request('https://identi.ca/api/statuses/update.xml',
... 'POST', ②
... urlencode(data), ③
... headers={'Content-Type': 'application/x-www-form-urlencoded'}) ④
- Строка 6. Так
httplib2обрабатывает аутентификацию. Сохраните свое имя пользователя и пароль с помощью методаadd_credentials(). Когдаhttplib2пытается выдать запрос, сервер ответит кодом состояния 401 Unauthorized и укажет, какие методы аутентификации он поддерживает (в заголовкеWWW-Authenticate).httplib2автоматически создаст заголовокAuthorizationи повторно запросит URL. - Строка 8. Второй параметр – это тип HTTP запроса, в данном случае
POST. - Строка 9. Третий параметр – это полезная нагрузка для отправки на сервер. Мы отправляем словарь в кодировке URL с сообщением о статусе.
- Строка 10. Наконец, нам нужно сообщить серверу, что полезная нагрузка – это данные в кодировке URL.
Третий параметр метода add_credentials() – это домен, в котором действительны учетные данные. Вы всегда должны указывать его! Если вы выйдете из домена, а затем повторно используете объект httplib2.Http на другом аутентифицированном сайте, httplib2 может выдать имя пользователя и пароль от одного сайта на другой сайт.
Вот что передается по сети:
# продолжение предыдущего примера
send: b'POST /api/statuses/update.xml HTTP/1.1
Host: identi.ca
Accept-Encoding: identity
Content-Length: 32
content-type: application/x-www-form-urlencoded
user-agent: Python-httplib2/$Rev: 259 $
status=Test+update+from+Python+3'
reply: 'HTTP/1.1 401 Unauthorized' ①
send: b'POST /api/statuses/update.xml HTTP/1.1 ②
Host: identi.ca
Accept-Encoding: identity
Content-Length: 32
content-type: application/x-www-form-urlencoded
authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ③
user-agent: Python-httplib2/$Rev: 259 $
status=Test+update+from+Python+3'
reply: 'HTTP/1.1 200 OK' ④
- Строка 10. После первого запроса сервер отвечает кодом состояния 401 Unauthorized.
httplib2никогда не будет отправлять заголовки аутентификации, если сервер явно не запрашивает их. А именно так сервер запрашивает их. - Строка 11.
httplib2немедленно поворачивается и запрашивает тот же URL адрес во второй раз. - Строка 16. На этот раз он включает имя пользователя и пароль, которые мы добавили с помощью метода
add_credentials(). - Строка 20. Это сработало!
Что сервер отправляет обратно после успешного запроса? Это полностью зависит от API веб-службы. В некоторых протоколах (таких как протокол публикации Atom) сервер отправляет обратно код состояния 201 Created и местоположение вновь созданного ресурса в заголовке Location. Identi.ca отправляет обратно 200 OK и документ XML, содержащий информацию о вновь созданном ресурсе.
# продолжение предыдущего примера
>>> print(content.decode('utf-8')) ①
<?xml version="1.0" encoding="UTF-8"?>
<status>
<text>Test update from Python 3</text> ②
<truncated>false</truncated>
<created_at>Wed Jun 10 03:53:46 +0000 2009</created_at>
<in_reply_to_status_id></in_reply_to_status_id>
<source>api</source>
<id>5131472</id> ③
<in_reply_to_user_id></in_reply_to_user_id>
<in_reply_to_screen_name></in_reply_to_screen_name>
<favorited>false</favorited>
<user>
<id>3212</id>
<name>Mark Pilgrim</name>
<screen_name>diveintomark</screen_name>
<location>27502, US</location>
<description>tech writer, husband, father</description>
<profile_image_url>http://avatar.identi.ca/3212-48-20081216000626.png</profile_image_url>
<url>http://diveintomark.org/</url>
<protected>false</protected>
<followers_count>329</followers_count>
<profile_background_color></profile_background_color>
<profile_text_color></profile_text_color>
<profile_link_color></profile_link_color>
<profile_sidebar_fill_color></profile_sidebar_fill_color>
<profile_sidebar_border_color></profile_sidebar_border_color>
<friends_count>2</friends_count>
<created_at>Wed Jul 02 22:03:58 +0000 2008</created_at>
<favourites_count>30768</favourites_count>
<utc_offset>0</utc_offset>
<time_zone>UTC</time_zone>
<profile_background_image_url></profile_background_image_url>
<profile_background_tile>false</profile_background_tile>
<statuses_count>122</statuses_count>
<following>false</following>
<notifications>false</notifications>
</user>
</status>
- Строка 2. Помните, что данные, возвращаемые
httplib2, всегда являются байтами, а не строкой. Чтобы преобразовать этот объект в строку, вам необходимо декодировать его, используя правильную кодировку символов. API Identi.ca всегда возвращает результаты в UTF-8, поэтому тут всё просто. - Строка 5. Это текст сообщения о статусе, которое мы только что опубликовали.
- Строка 10. Для нового сообщения о статусе существует уникальный идентификатор. Identi.ca использует его для создания URL адреса для просмотра сообщения в Интернете.
И вот оно:
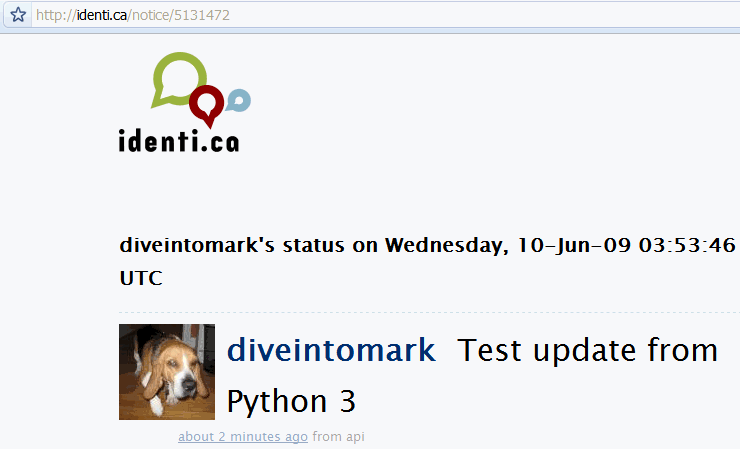
14.7 Помимо HTTP POST
HTTP не ограничивается GET и POST. Это, безусловно, самые распространенные типы запросов, особенно в веб-браузерах. Но API веб-сервиса может выходить за рамки GET и POST, и httplib2 к этому готов.
# продолжение предыдущего примера
>>> from xml.etree import ElementTree as etree
>>> tree = etree.fromstring(content) ①
>>> status_id = tree.findtext('id') ②
>>> status_id
'5131472'
>>> url = 'https://identi.ca/api/statuses/destroy/{0}.xml'.format(status_id) ③
>>> resp, deleted_content = h.request(url, 'DELETE') ④
- Строка 3. Сервер вернул XML, верно? Мы умеем парсить XML.
- Строка 4. Метод
findtext()ищет первый экземпляр данного выражения и извлекает его текстовый контент. В этом случае мы просто ищем элемент<id>. - Строка 7. На основе текстового контента элемента
<id>мы можем создать URL адрес, чтобы удалить только что опубликованное сообщение о статусе. - Строка 8. Чтобы удалить сообщение, просто отправьте HTTP запрос
DELETEна этот URL.
Вот что передается по сети:
send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ①
Host: identi.ca
Accept-Encoding: identity
user-agent: Python-httplib2/$Rev: 259 $
'
reply: 'HTTP/1.1 401 Unauthorized' ②
send: b'DELETE /api/statuses/destroy/5131472.xml HTTP/1.1 ③
Host: identi.ca
Accept-Encoding: identity
authorization: Basic SECRET_HASH_CONSTRUCTED_BY_HTTPLIB2 ④
user-agent: Python-httplib2/$Rev: 259 $
'
reply: 'HTTP/1.1 200 OK' ⑤
>>> resp.status
200
- Строка 1. «Удалить это сообщение о статусе».
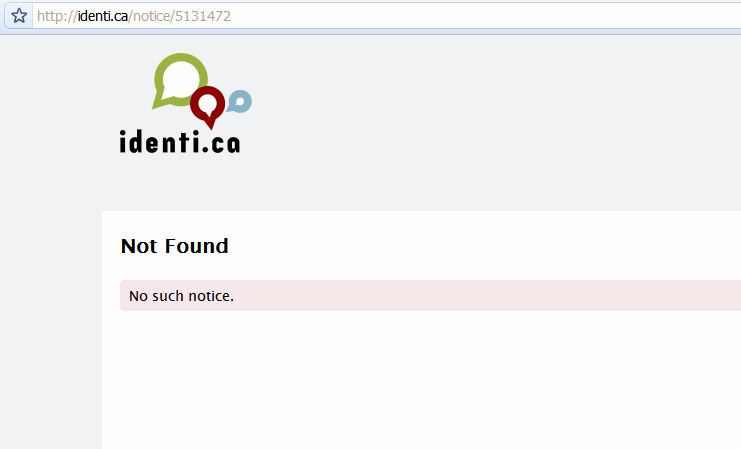
- Строка 7. Извини, Дейв, боюсь, я не смогу этого сделать.
- Строка 8. «Неавторизован»? Хм. Удалите это сообщение статуса, пожалуйста...
- Строка 11. … а вот мои имя пользователя и пароль.
- Строка 15. «Считай, что всё сделано!»
И просто так, пшик, оно исчезло.
14.8 Материалы для дальнейшего чтения
httplib2:
httplib2страница проекта- Больше примеров кода
httplib2 - Doing HTTP Caching Right: Introducing
httplib2 httplib2: HTTP Persistence and Authentication
HTTP кеширование:
- http Caching Tutorial by Mark Nottingham
- How to control caching with http headers on Google Doctype
RFC:
- RFC 2616: HTTP
- RFC 2617: HTTP Basic Authentication
- RFC 1951: deflate compression
- RFC 1952: gzip compression