4.1 – Введение в основные типы данных
Биты, байты и адресация памяти
В уроке «1.3 – Знакомство с переменными в C++» мы говорили о том факте, что переменные – это имена фрагментов памяти, которые можно использовать для хранения информации. Вкратце, компьютеры имеют оперативную память (RAM), доступную для использования программами. Когда переменная определена, часть этой памяти выделяется для этой переменной.
Наименьшая единица памяти – это бит (сокращенно от «binary digit», «двоичная цифра»), которая может содержать значение 0 или 1. Вы можете представить бит как обычный выключатель света – либо свет выключен (0), либо или он включен (1). Промежуточного значения нет. Если вы посмотрите на случайный сегмент памяти, всё, что вы увидите, это …011010100101010… или подобную комбинацию.
Память организована в последовательные блоки, называемые адресами памяти (или, для краткости, просто адресами). Подобно тому, как почтовый адрес может использоваться для поиска заданного дома на улице, адрес памяти позволяет нам находить и получать доступ к содержимому памяти в определенном месте.
Возможно, покажется удивительным, что в современных компьютерных архитектурах каждый бит не имеет собственного уникального адреса памяти. Это связано с тем, что количество адресов памяти ограничено, а побитовый доступ к данным редко бывает необходим. Вместо этого каждый адрес памяти содержит 1 байт данных. Байт – это группа битов, которые используются как единое целое. Современный стандарт подразумевает, что байт состоит из 8 последовательных битов.
Ключевой момент
В C++ мы обычно работаем с фрагментами данных «байтового размера».
На следующем рисунке показаны несколько последовательных адресов памяти вместе с соответствующими байтами данных:
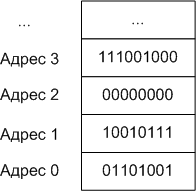
В качестве отступления...
Некоторые старые или нестандартные машины могут иметь байты другого размера (от 1 до 48 бит), однако нам обычно не нужно беспокоиться об этом, поскольку современный стандарт де-факто подразумевает, что 1 байт составляет 8 бит. В этих обучающих статьях мы предполагаем, что байт равен 8 битам.
Типы данных
Поскольку все данные на компьютере представляют собой всего лишь последовательность битов, мы используем тип данных (часто называемый для краткости «типом»), чтобы сообщить компилятору, как интерпретировать содержимое памяти тем или иным образом. Вы уже видели один пример типа данных: целочисленное значение. Когда мы объявляем переменную как целочисленное значение, мы сообщаем компилятору, что «часть памяти, которую использует эта переменная, будет интерпретироваться как целочисленное значение».
Когда вы присваиваете объекту значение, компилятор и CPU заботятся о кодировании вашего значения в соответствующую для этого типа данных последовательность битов, которые затем сохраняются в памяти (помните: память может хранить только биты). Например, если вы присваиваете целочисленному объекту значение 65, это значение преобразуется в последовательность битов 0100 0001 и сохраняется в памяти, назначенной объекту.
И наоборот, когда объект вычисляется для получения значения, эта последовательность битов восстанавливается обратно в исходное значение. Это означает, что 0100 0001 конвертируется обратно в значение 65.
К счастью, компилятор и процессор здесь делают всю тяжелую работу, поэтому вам обычно не нужно беспокоиться о том, как значения преобразуются в битовые последовательности и обратно.
Всё, что вам нужно сделать, это выбрать тип данных для вашего объекта, который лучше всего соответствует необходимому вам использованию.
Основные типы данных
C++ имеет встроенную поддержку множества различных типов данных. Они называются базовыми типами данных, но часто неофициально называются примитивными типами или встроенными типами.
Вот список основных типов данных, некоторые из которых вы уже видели:
| Типы | Категория | Значение | Пример |
|---|---|---|---|
| float double long double |
Число с плавающей запятой | Число с дробной частью | 3.14159 |
| bool | Целое число (логическое) |
Истина (true) или ложь (false) | true |
| char wchar_t char8_t (C++20) char16_t (C++11) char32_t (C++11) |
Целое число (символ) |
Один символ текста | 'c' |
| short int long long long (C++11) |
Целое число (целочисленное значение) |
Положительне и отрицательные числа, включая 0 | 64 |
| std::nullptr_t (C++11) | Нулевой указатель | Нулевой указатель | nullptr |
| void | Без типа | Нет типа | не доступно |
Эта глава посвящена подробному изучению этих базовых типов данных (кроме std::nullptr_t, который мы обсудим, когда будем говорить об указателях). C++ также поддерживает ряд других более сложных типов, называемых составными типами. Составные типы мы рассмотрим в следующей главе.
Примечание автора
Термины «целочисленное значение» (integer) и «целое число» (integral) похожи, но имеют разные значения. Целочисленное значение (integer) – это особый тип данных, который содержит недробные числа, такие как положительные целые числа, 0 и отрицательные целые числа. Целое число (integral) означает «как целое число». Чаще всего целое число используется как часть термина целочисленный тип, который включает все логические, символьные и целочисленные типы (также перечисляемые типы, которые мы обсудим в главе 8). Целочисленные типы названы так, потому что они хранятся в памяти как целые числа, хотя их поведение может различаться (что мы увидим позже в этой главе, когда будем говорить о символьных типах).
Суффикс _t
Многие из типов, определенных в новых версиях C++ (например, std::nullptr_t), используют суффикс _t. Этот суффикс означает «тип», и это обычная номенклатура, применяемая к современным типам.
Если вы видите что-то с суффиксом _t, вероятно, это тип. Но многие типы не имеют суффикса _t, поэтому он применяется не всегда.