Анатомия асинхронных фреймворков в С++ и других языках
Привет! В этой статье я расскажу об устройстве асинхронных движков с корутинами и без них. Для начала сосредоточимся не на конкретном движке, а на том, почему во всех популярных языках программирования появились корутины, и чем они так хороши. Это может быть интересно не только C++-разработчикам, но и всем, кто занимается разработкой сетевых приложений или интересуется архитектурой современных фреймворков.
Пройдёмся по разным архитектурам построения серверов – от самой простой синхронной к более интересным, посмотрим на типичную архитектуру корутинового движка, а после окунёмся в дебри C++ и взглянем на самое страшное на примере нашего фреймворка userver.
Пишем синхронный сервер
Представьте, что у вашего сервиса очень маленькая нагрузка – 100 rps, и вам дали задачу написать простой сервер, понятный каждому второму школьнику. У вас получится что-то наподобие следующего:
void naive_accept() {
for (;;) {
auto new_socket = accept(listener);
std::thread thrd([socket = std::move(new_socket)] {
auto data = socket.receive();
process(data);
socket.send(data);
});
thrd.detach();
}
}
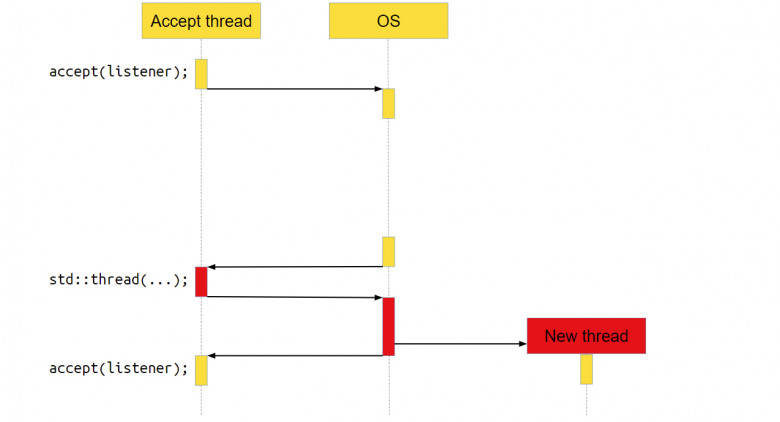
Сервер принимает новые соединения в бесконечном цикле с помощью функции accept. Как только у нас появляется новое соединение socket, мы передаём его в отдельный поток выполнения и уже в этом потоке с ним работаем. Мы считываем из socket’а данные, обрабатываем их и отправляем обратно по socket’у ответ. Всё очень просто. Как такой сервер выглядит для операционной системы (ОС)?
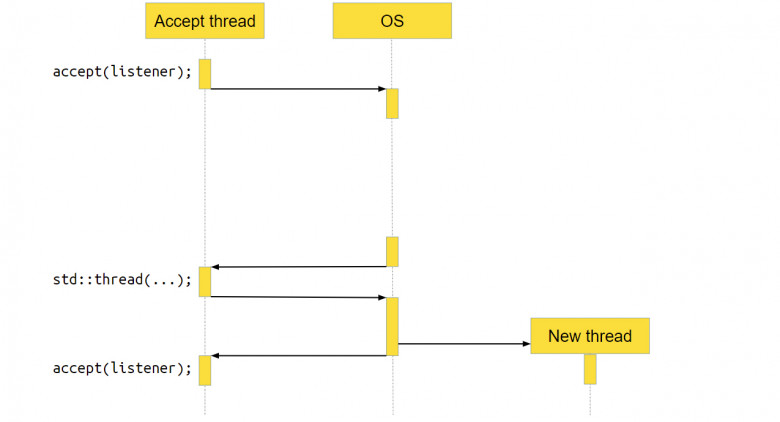
Мы вызываем accept. accept – это системный вызов, то есть функция, которая пойдёт в операционку, и уже операционка выполнит необходимые действия, в данном случае – вернёт новое соединение.
Но нового соединения может и не быть, если пользователи нашего серверного приложения ещё не сделали к нему запрос. В этом случае ОС приостановит приложение, переключит контекст на другое, и ядро процессора будет работать с другой программой.
В какой-то момент новое соединение появится, операционная система это заметит и вернёт нашему приложению управление. Программа продолжит работать как ни в чём не бывало.
Переходим к следующей строке кода. Там создаётся std∷thread, куда мы передаём socket. За вызовом std∷thread тоже находится системный вызов, достаточно тяжёлый на многих операционных системах. Мы получаем новый поток выполнения. После этого всё продолжается в бесконечном цикле: мы опять вызываем accept, идём в операционную систему, делаем системный вызов, а ОС приостанавливает наш поток.
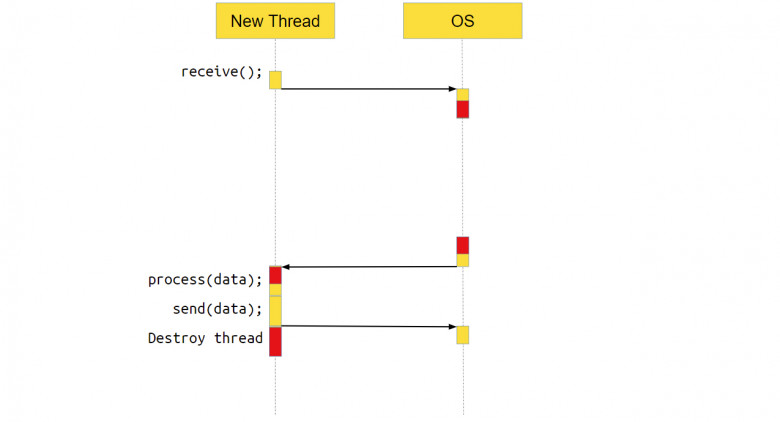
Что делает новый поток?
Что происходит с потоком, который получил новое соединение и обрабатывает его? В нём тоже выполняется системный вызов receive. То есть мы идём в систему, говорим: «Эй, операционка, дай нам данных! – а ОС отвечает, – Ой, на socket нет данных, пусть поток поспит, пока данные не появятся».
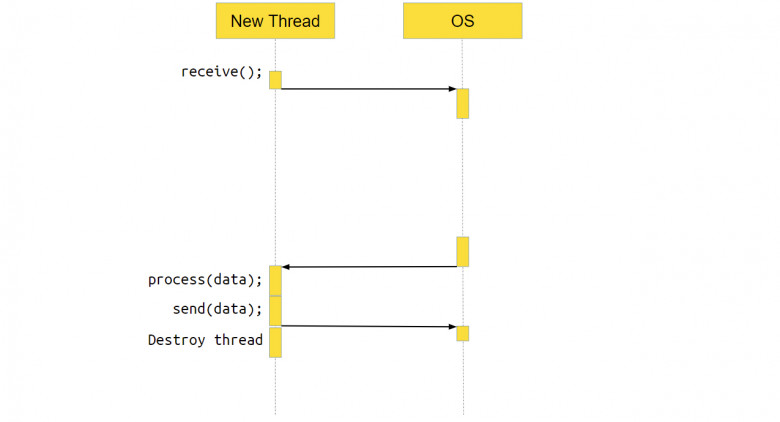
Когда данные появляются, ОС переключает выполнение обратно на наше приложение, оно обрабатывает данные и отправляет их через ОС по socket пользователю. После этого поток уничтожается – он своё дело сделал.
Плюсы и минусы наивного подхода
Плюсы описанного подхода очевидны – получается очень простой сервер. Его легко написать, легко читать, он понятный. Но есть и минусы, например, сервер весьма неэффективен, потому что мы делаем много тяжёлых операций, которых можно было не делать.
В табличке показано, сколько времени занимает та или иная операция:
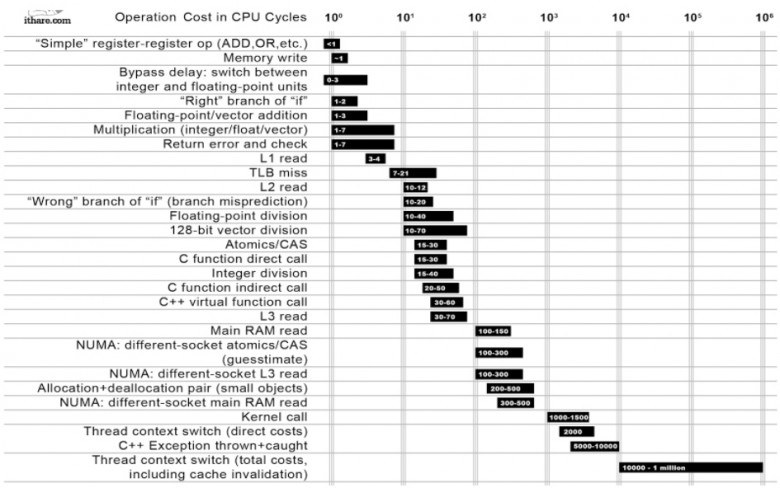
Самые «дешёвые» операции стоят наверху. Например, перемещение данных из регистра в регистр занимает меньше одного такта. А самые «дорогие» операции находятся внизу. И среди этих операций есть системный вызов, который занимает 1000–1500 тактов. А в самом-самом низу находится системный вызов, который приводит к переключению контекста. Такое переключение с возвратом обратно в приложение занимает от 10 тысяч тактов до миллиона.
Если наше приложение занимается в основном тем, что получает данные и отправляет их куда-то, то есть является I/O bound приложением, количество переключений контекста может быть очень большим. Если от них избавиться, приложение станет работать в 10, 20, 30, а то и в 100 раз быстрее.
Другой недостаток этой архитектуры – то, что мы порождаем новый поток на каждый пользовательский запрос. Для некоторых приложений это может быть недопустимо. Например, приложения на Python, как правило, однопоточные. И создать в них новый поток – весьма своеобразная задача. Следовательно, для Python такая архитектура не подойдёт.
Создание потока – дорогая и тяжёлая операция. Если бы мы переиспользовали потоки, то получили бы дополнительный прирост производительности, а если бы работа шла в одном потоке, наша архитектура подходила бы для Python.
Пишем асинхронный сервер
Представим себе, что нагрузка возросла так, что самый простой сервер нас уже не устраивает. Нужно что-то более производительное – асинхронный сервер!
В чём его отличие? В синхронном сервере мы говорили: «Операционная система, дай нам новый socket», – и пока новый socket не появлялся, операционная система приостанавливала поток. Она возобновляла работу, когда событие случалось – когда мы получали новое соединение.
А в асинхронном сервере мы запрашиваем у операционной системы уже случившиеся события. Мы можем работать с ними сразу – выполнить какую-либо функцию или callback, связанный с этим событием. Мы забираем то, что уже готово, тем самым избавляясь от переключений контекста. В псевдокоде это выглядит примерно так:
void async_accept() {
accept(listener, [](socket_t socket) {
async_accept();
socket.receive(
[socket](std::vector<unsigned char> data) {
process(data);
socket.send(data, kNoCallback);
});
});
}
Есть функция async_accept, и в ней первой же строчкой мы вызываем асинхронный приём нового соединения – accept. В этот момент мы говорим ОС: «Операционка, начинай отслеживать событие получения новых socket’ов на этом socket listener». Когда событие произойдёт, ОС сообщит о нём фреймворку, внутренности фреймворка вызовут callback [](socket_t socket) и передадут в него новый socket.
Асинхронный accept отрабатывает сразу, то есть мы не ждём, пока появится socket. Мы сказали операционке наблюдать за новыми событиями, и вызов тут же отработал – мы вышли из функции async_accept.
А вот когда socket появился, ОС сообщает об этом нашему движку, и движок вызывает callback. Внутри callback’а опять вызывается async_accept. Мы как бы говорим операционке: «Продолжай следить за новыми соединениями».
А ещё говорим: «За новым socket’ом тоже приглядывай. Когда там появятся данные, позови вот этот callback [socket](std::vector data) и передай в него вектор с данными». И когда данные появляются, ОС передаёт их в callback. Там эти данные обрабатываются и посылаются наружу через socket.send.
Как выглядит такое взаимодействие на диаграмме?
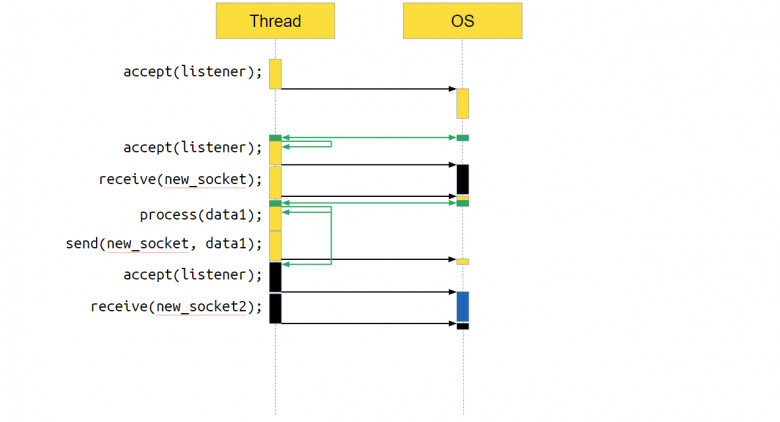
В самом начале мы вызываем accept и говорим системе: «Следи, появятся ли новые события». А спустя какое-то время движок идёт в ОС и спрашивает: «Ну что? Какие события свершились?» И операционная система, например, может ответить: «Есть новое соединение».
Движок отвечает: «Замечательно! Выполняем callback» – а callback первым делом запрашивает у ОС, чтобы она следила за новыми соединениями. Затем работа продолжается, мы вызываем receive для получения новых данных. Говорим операционке: «Отслеживай новые события». Всё, движку пока больше делать нечего.
Через некоторое время движок снова спрашивает: «Операционная система, какие-нибудь новые события случились? Есть над чем мне поработать?» И ОС может ответить: «Да, вот сразу несколько. Во-первых, пришли данные, которые вы запрашивали на socket’е, во-вторых, появилось новое соединение».
В этом случае асинхронный движок выполнит три callback’а: тот, который обработает данные; тот, который отправит данные; и callback, который связан с обработкой нового соединения.
Это уже второе соединение. То есть мы обрабатываем два соединения и accept в рамках одного потока. Это отличная архитектура, которая подходит Python. В чём же проблема с таким подходом, чего нам не хватает? Всё просто – не хватает возможности запускать пользовательские задачи в параллель от выполняемого в данный момент кода.
Запуск пользовательских задач
socket.receive([socket](std::vector<unsigned char> data) {
auto task = Async(process1, data);
process(data);
task.wait();
socket.send(data, kNoCallback);
});
Пользователи могут захотеть запустить обработку в отдельной задаче параллельно с основной, а потом подождать, пока обе обработки завершатся.
Проблема в том, что операционная система ничего не знает о наших подзадачах. Они внутри движка, а значит нужно учить операционную систему, что у нас есть какие-то свои подзадачи. С ОС в таком случае придётся общаться через системные вызовы, а это не очень эффективно. Другой вариант – завести очередь готовых к выполнению задач. В этом случае синхронный движок будет выглядеть так:
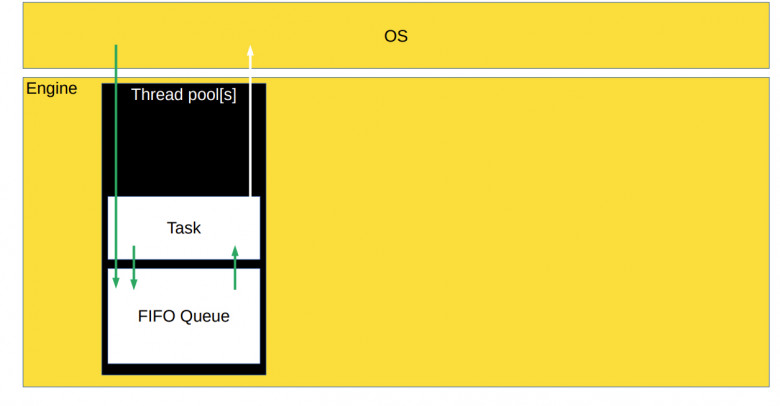
В движке есть thread pool, где хранится очередь готовых к выполнению задач. В thread pool поступают задачи из движка, который собирает события из операционки и добавляет в очередь задач готовые к выполнению callback’и.
Сам thread pool вытаскивает задачи из очереди и обсчитывает их. Во время обсчёта задача может сказать операционной системе: «Начинай следить за какими-то другими событиями». Задача может породить другие задачи, готовые к выполнению. И в этом случае новые задачи также будут помещены в очередь.
Thread pool при этом может состоять как из одного потока, так и из нескольких, в зависимости от того, как вы настроили движок, или как он написан.
Но есть нюанс. Такая схема работает хорошо в идеальном мире, где у ОС есть полный набор асинхронных методов под все наши желания. К несчастью, мы живем не в самом идеальном мире, и у операционок не всегда есть асинхронные варианты нужных системных вызовов. Например, посмотреть содержимое директории и прочитать оттуда файл асинхронно может далеко не каждая операционка.
Поэтому во многих случаях заводится отдельный thread pool для блокирующих задач, которые нет возможности асинхронно выполнять в ОС. Он нужен для того, чтобы потоки из основного thread pool не застывали на блокирующих системных вызовах, чтобы основной thread pool занимался только CPU bound-задачами, то есть максимально эффективно загружал процессор.
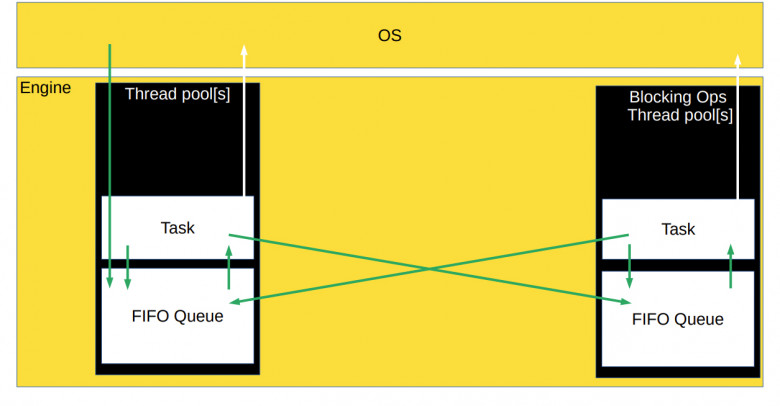
Из очереди блокирующих задач готовые к выполнению callback’и могут попадать в очередь CPU bound-задач, а задачи из CPU bound pool’а могут закидываться в очередь блокирующих задач. То есть все очереди могут общаться друг с другом и обмениваться задачами.
А как же синхронизация?
И всё бы ничего, но двух очередей не хватает для сценариев с одновременным доступом к одним и тем же данным из разных потоков. Для правильной работы приложения необходимо защищать общие данные примитивами синхронизации, например мьютексами. Снова возникает риск блокировки потока.
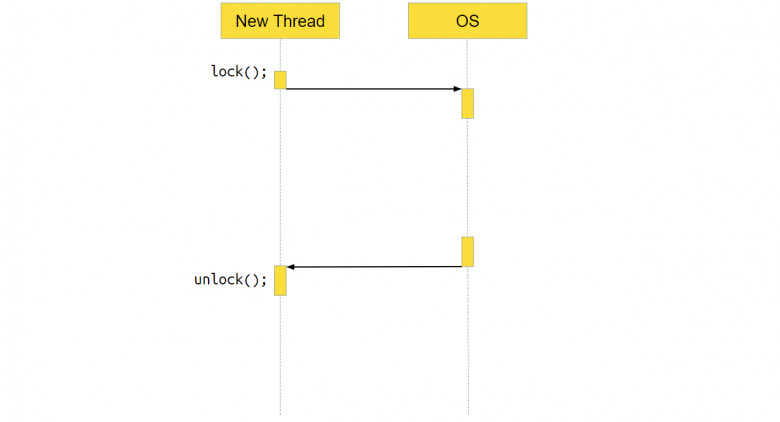
Например, если на уже заблокированном стандартном мьютексе вызвать метод lock, произойдёт системный вызов, управление передастся ОС, и система поймёт: мьютекс заблокирован, потоку делать нечего, его надо приостановить, переключить контекст и работать с другим приложением. А вот когда мьютекс разблокируется, поток нужно будет разбудить и сказать, что мьютекс успешно залочился.
Минус в том, что на какое-то время поток застывает и ничего не делает, а это для асинхронного движка не очень хорошо. Приложение простаивает.
Чтобы этого не происходило, можно написать свои мьютексы с callback’ами.
mutex.lock([data = std::move(data), socket = std::move(socket)]() {
process2(shared_resource, data);
socket.send(data, kNoCallback);
});
Например, можно сделать мьютекс с функцией lock, куда мы передаём callback, который нужно выполнить, когда мьютекс будет успешно захвачен. Под капотом этот lock может выглядеть как-то так:
template <class Functor>
void lock(Functor f) {
auto lock = this->try_lock();
if (lock) {
f();
} else {
wait_for_unlock(std::move(f));
}
}
Когда вызывается lock(), мы пытаемся захватить мьютекс. Если он успешно захвачен, сразу же выполняется callback. Если же callback не выполнен, его нужно поместить в очередь задач, где он будет ждать освобождения мьютекса. Так в схему асинхронного движка добавляется ещё один блок – приостановленные задачи, которые чего-то ждут.
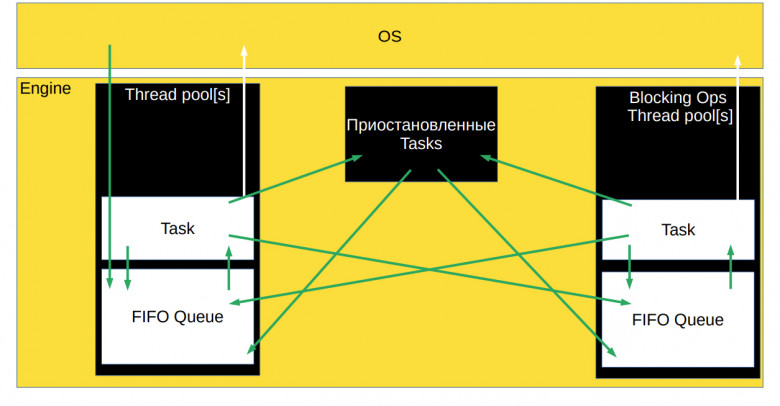
Задачи могут попадать туда из thread pool’а и возвращаться в очередь готовых к выполнению задач, когда их можно разблокировать. В блок могут попадать задачи и из других thread pool’ов, например, из потока блокирующих операций. Главное, что в нужный момент задача вернётся обратно в очередь готовых к выполнению задач нужного thread pool’а.
Плюсы и минусы асинхронного сервера без корутин
Так мы получили асинхронный сервер без корутин. Его плюсы очевидны – всё очень эффективно. Мы можем в один поток обрабатывать множество соединений, нет лишних переключений контекста, а ресурс CPU потребляется минимально. Проблема же состоит в том, что со временем код становится нечитаемым.
void async_accept() {
accept(listener, [](socket_t socket) {
async_accept();
auto something = Async(process1, {42});
auto& socket_ref = *socket; socket_ref.receive(
[socket = std::move(socket), something = std::move(something)](std::vector<unsigned char> data) mutable {
auto task = Async(process1, data);
process(data);
task.wait();
auto& socket_ref = *socket; socket_ref.send(data, [data, socket = std::move(socket), something = std::move(something)]() mutable {
mutex.lock([data = std::move(data), socket = std::move(socket), something = std::move(something)]() mutable {
process2(shared_resource, data);
socket->send(data, kNoCallback);
});
});
});
});
}
Когда пример маленький, простой, и мы не передаём много данных между callback’ами, всё читается более-менее нормально. Но когда объёмы данных возрастают и появляется несколько переменных, которые нужно передавать между callback’ами, всё становится значительно сложнее.
Приходится аккуратно следить за временем жизни переменных, правильно и эффективно передавать их в callback’и, не забывать перемещать. Во многих местах нельзя передавать переменные по ссылке, потому что образуется висячая ссылка – код становится ещё и опасным.
Написание кода усложняется, как и его читаемость, работать с ним можно, но неприятно (конечно, если вы не из тех, кому такое нравится). Тут нам на помощь приходят корутины. Смотрим на третий тип архитектуры – асинхронный движок с корутинами.
Асинхронный сервер с корутинами
coro_future coro_accept_stackles() {
for (;;) {
auto new_socket = co_await accept(listener);
auto task = Async([socket = std::move(new_socket)]() -> coro_future {
auto data = co_await socket.receive();
process(data);
co_await socket.send(data);
co_return;
});
task.Detach();
}
}
Как работает такая архитектура? В самом начале мы принимаем socket. При этом рядом пишем ключевое слово co_await для корутин. Приняли socket, создаём новую задачу. Внутри задачи мы получаем данные с socket’а, обрабатываем их и отправляем результат наружу.
При этом всё крутится в бесконечном цикле и код становится очень похожим на самый первый синхронный сервер, который мы писали так, чтобы он был понятен даже школьникам, – практически буква в букву. Разница только в том, что добавляются ключевые слова для работы со stackless-корутинами: co_await, co_return и т. д.
Но можно ли сделать код ещё более похожим на самый простой синхронный сервер? Можно! Для этого нужно воспользоваться не stackless, а stackfull-корутинами. Так код станет один в один таким же, как и у синхронного сервера. Забегая вперёд скажу, что эффективность останется на уровне асинхронного.
Асинхронный сервер с корутинами vs. синхронный:
|
|
Однако при переходе на stackfull-корутины появляются небольшие накладные расходы: увеличивается потребление оперативной памяти, чуть замедляются отмены. Тут каждый выбирает для себя, что ему ближе – код, более похожий на синхронный и более простой, или наименьшее использование оперативной памяти.
Устройство корутинового движка
Давайте взглянем, как корутиновый движок выглядит под капотом.
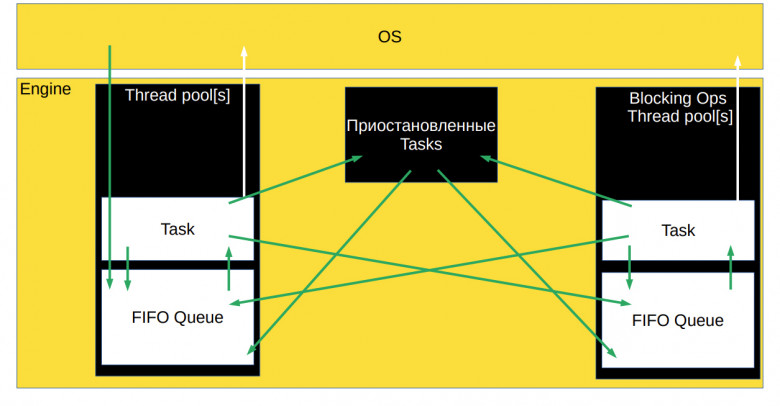
Схема получается такая же, что была у асинхронного движка без корутин. Всё дело в том, что корутины – это почти callback.
coro_future coro_accept_stackles() {
for (;;) {
auto new_socket = co_await accept(listener);
auto task = Async([socket = std::move(new_socket)]() -> coro_future {
auto data = co_await socket.receive();
process(data);
co_await socket.send(data);
co_return;
});
task.Detach();
}
}
Когда мы пишем co_await, компилятор смотрит всё, что есть рядом в коде, и из этого хитрым способом делает callback, который передаёт в функцию accept.
Когда компилятор видит co_await внутри отдельной задачи, он собирает лежащие рядом переменные, делает из них callback и подсовывает его в receive. Так происходит в случае stackless-корутин.
В случае stackfull-корутин мы как бы превращаем весь наш стек в подобие callback’а. Всё, что есть на стеке, превращается в отдельную задачу, которая передаётся в очередь, откуда её можно запустить и передать в асинхронные методы. С корутинами и асинхронностью у нас всё работает очень эффективно, так же, как было в случае обычного асинхронного сервера с callback’ом, а код остаётся простым и читаемым.
Но есть и минусы. Под капотом у такого асинхронного сервера с корутинами творится лютая жесть. Причём такая же жесть, как если бы мы писали просто асинхронный сервер. И если вы – матёрый разработчик, вам эта жесть может даже нравиться :-) Так что если вы эту жесть разрабатываете и получаете удовольствие, для вас минус может оказаться плюсом.
C++-хардкор
А теперь, как я и обещал, обратимся к конкретному примеру. Посмотрим, как с этой жестью под капотом работает группа общих компонент в Яндексе. У нас есть свой асинхронный фреймворк, который называется userver. Я покажу, как мы реализовали в нём неблокирующий асинхронный мьютекс, используя корутины и асинхронщину.
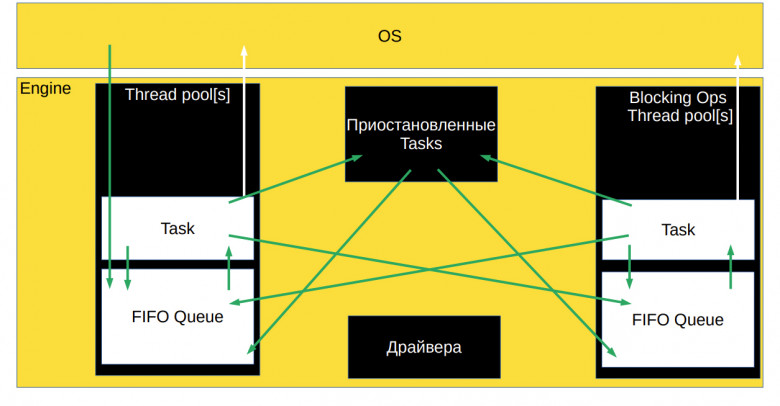
Архитектура userver напоминает большинство асинхронных фреймворков. Правда, у нас есть ещё и асинхронные драйверы для разных баз данных (PostgreSQL, MongoDB, Redis), socket’ов, DNS, http-протоколов и не http-протоколов. В общем, у нас практически под всё есть свои асинхронные драйверы и асинхронные примитивы синхронизаций.
Сделаем свой мьютекс. Асинхронный, эффективный, подходящий для асинхронного корутинового движка:
struct Mutex {
void lock();
void unlock();
private:
std::atomic<Coroutine*> owner_{nullptr};
};
В userver используются stackfull-корутины, поэтому никаких дополнительных ключевых слов не нужно, и мы можем сделать мьютекс, интерфейс которого совпадает с std∷mutex. То есть с нашим мьютексом можно использовать std::unique_lock.
У мьютекса, как ни удивительно, есть методы lock и unlock, и для того, чтобы всё это заработало, внутри класса мьютекса нам понадобится атомарная переменная owner_. В этой переменной мы будем хранить указатель на ту корутину, которая в данный момент владеет мьютексом. Если мьютексом никто не владеет, в этой переменной хранится nullptr.
Метод lock будет выглядеть следующим образом:
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current))
return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
В самом начале мы получаем указатель на текущую корутину. Это та корутина, которая выполняет метод lock() в текущий момент. Ожидается, что мьютекс в данный момент никем не залочен, и мы атомарно пытаемся это проверить. Говорим: «Если мьютексом сейчас никто не владеет (то есть в атомарной переменной содержится nullptr), запиши туда в качестве владельца нашу корутину. И скажи мне, получилось это сделать или нет».
Если всё получилось и мьютекс захвачен, больше ничего не нужно, мы выходим из функции lock. Если же нам не повезло, и мьютексом уже владеет другая корутина, мы спускаемся ниже, заводим служебную переменную wait_manager, о которой я расскажу чуть позже, и пытаемся повторить процедуру с захватом мьютекса. Если на этот раз мьютекс разлочен, мы выходим из функции lock и уничтожаем локальные переменные.
Если мьютекс ещё захвачен, нужно дождаться разблокировки, а корутину приостановить и переместить в очередь приостановленных задач, неготовых к выполнению. Как же это сделать?
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
// ...
};
Внутри корутины есть метод Sleep. Он, как ни странно, приостанавливает корутину. Она перестаёт выполняться до тех пор, пока её не позовут в методе Wakeup.
В Sleep передаётся WaitStrategy – базовый класс, у которого всего две виртуальные функции.
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
AfterAsleepвызывается сразу же после того, как корутина была остановлена. В этом методе обычно запускаются механизмы, которые могут разбудить кортуину.BeforeAwakeвызывается перед тем, как корутина будет разбужена. В этом методе останавливаются все механизмы для пробуждения корутины.
struct Mutex {
void lock();
void unlock();
private:
std::atomic<Coroutine*> owner_{nullptr};
WaitList lock_waiters_;
};
Также в класс мьютекса мы добавляем переменную WaitList. Это очередь корутин, ожидающих разлочивания на этом мьютексе. Если бы мы работали со стандартным мьютексом ОС, такая очередь держалась бы где-то внутри системы. Но так как мы используем свои примитивы синхронизации, необходимости ходить в операционку нет. Мы можем держать всю информацию у себя, например, информацию о том, кто ждёт на мьютексе, держать в самом мьютексе.
Что же в это время происходит в функции lock? Мы создаём переменную класса MutexWaitStrategy, отнаследованного от WaitStrategy. Созданную переменную мы передаём в метод Sleep. И это место – моё самое любимое во всех корутиновых движках, потому что здесь мы можем использовать стек вместо кучи.
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current))
return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
Например, движку где-то глубоко внутри нужно создать односвязный или двусвязный список и в этот двусвязный список поместить корутину, которая сейчас должна приостановиться. Можно воспользоваться стандартным контейнером, но в этом случае внутри движка будут происходить медленные динамические аллокации при вставке новых элементов.
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current))
return;
expected = nullptr;
impl::ListNode<Coroutine*> node{current};
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
А можно воспользоваться интрузивными списками и разместить node этого листа на стеке корутины, которую мы вот-вот приостановим. Когда корутина будет приостановлена, этим стеком всё ещё можно пользоваться, можно даже изменять корутину, потому что она приостановлена, но не уничтожена. Благодаря этому мы можем создать всё, что нужно движку для работы прямо на стеке, и полностью избежать динамических аллокаций внутри движка.
Движемся дальше. Создаём вспомогательную переменную MutexWaitStrategy, и в конструкторе этой переменной захватываем lock, который защищает WaitList, то есть список корутин, ожидающих на мьютексе.
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
Этот lock также поможет не пропустить нотификацию о том, что мьютекс разлочился.
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current))
return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
Создаём Wait_manager, делаем compare_exchange_strong. Не повезло – мьютекс ещё захвачен, идём в метод Sleep. Внутри Sleep корутина будет остановлена, затем выполнится метод AfterAsleep из MutexWaitStrategy. В этом методе мы добавим нашу корутину в список ожидающих на мьютексе.
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
Разлочиваем lock, после чего корутина снимается с thread и ждёт, пока мьютекс будет разлочен. В это время движок подхватывает другую, готовую к выполнению задачу, и начинает выполнять её, благодаря чему thread не простаивает. Затем корутина, которая до этого захватила мьютекс, вызывает unlock:
void Mutex::unlock() {
[[maybe_unused]] const auto old_owner = owner_.exchange(nullptr);
assert(old_owner == GetCurrentCoro());
WaitList::Lock lock(lock_waiters_);
lock_waiters_.WakeupOne(lock);
}
В unlock записывается, что мьютексом больше никто не владеет, owner снова принимает значение nullptr. Проходит проверка – мы убеждаемся, что мьютекс разлочивает та же корутина, которая его залочила. После этого захватывается блокировка для WaitList, и мы в WaitList вызываем метод «разбуди-ка одну корутину, которая дольше всего ожидает выполнения».
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
WaitList будит корутину и вызывает метод MutexWaitStrategy::BeforeAwake перед тем, как корутина совсем проснётся. В этом методе BeforeAwake мы захватываем lock. Удаляем корутину из списка ожидающих на мьютексе и проваливаемся вниз после метода Sleep.
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current))
return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
Ожидаем, что с мьютексами никто не работает, и повторяем попытку захвата. Получаем мьютекс, который не блокирует std::thread. То есть std::thread переиспользуется, на нём считаются другие задачи.
Также этот мьютекс не переключает контекст и не общается лишний раз с операционной системой. ОС тоже не приостанавливает поток и не переключает контексты. Кроме того, мьютекс не аллоцирует память динамически. Всё, что нужно было динамически проаллоцировать, мы расположили на стеке корутины. Наш мьютекс хорош ещё и тем, что не требует callback’а, потому что работает с корутинами и выглядит, как обычный линейный код.
А что с производительностью? На бенчмарке, где в бесконечном цикле залочивается и разлочивается мьютекс из разных потоков, мы обгоняем по эффективности обычный std::mutex на одном и двух потоках, а для случаев большего contention я рекомендую использовать другие примитивы синхронизации из нашего фреймворка.
| Competing threads | std::mutex |
Mutex |
|---|---|---|
| 1 | 22 нс | 19 нс |
| 2 | 205 нс | 154 нс |
| 4 | 403 нс | 669 нс |
Что делать, если нужен мьютекс с таймаутом?
Прежде всего нужно добавить в мьютекс новую функцию try_lock_untill, в которую мы передаём дедлайн – указываем, до какого времени нужно пытаться залочить мьютекс.
struct Mutex {
void lock();
bool try_lock_untill(Deadline deadline);
void unlock();
private:
std::atomic<Coroutine*> owner_{nullptr};
WaitList lock_waiters_;
};
Чтобы всё это заработало, добавляем в корутину ещё пару методов.
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
Epoch, то есть количество засыпаний корутины, и Wakeup, который принимает эпоху на вход.
Теперь внутри WaitStrategy в конструкторе мы можем создать таймер на стеке без аллокации, зарядить этот таймер на нужный дедлайн и сохранить в нём эпоху, в которую мы хотим разбудить корутину. Когда таймер выстрелит, он разбудит корутину, если её эпоха не сменилась, а если корутина уже пробуждена – ничего не произойдёт. В методе AfterAsleep как раз можно запустить таймер, а в методе BeforeAwake остановить его, если корутину разбудили из-за мьютекса.
Получается гибкая схема с простым добавлением нового функционала. В какой-то момент мы поняли, что почти каждая операция обладает дедлайном, поэтому в userver код дублируется в WaitStrategy, а дедлайны вынесены в базовый класс. А ещё мы добавили в Sleep информацию о том, кто его разбудил: был ли он разбужен из-за WaitList или по таймауту.
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
const Deadline deadline;
protected:
~WaitStrategy() = default;
};
А что делать с отменами?
В корутину добавляются методы Cancel и IsCancelled, чтобы проверить, была отменена корутина или нет.
class Coroutine {
public:
// ...
WakeupReason Sleep(WaitStrategy& strategy);
bool IsCancelled() const;
void Cancel();
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
Где-то там находится булевая переменная, Sleep учится смотреть на неё в Wakeup. И, в принципе, это всё. Такую схему легко можно расширить.
В других корутиновых движках схема может отличаться. Например, в стандарте C++20 есть корутины, но они приостанавливаются несколько иначе. WaitStrategy называется Promise type, и устроено всё более наворочено и сложно. Однако нам хватает простого подхода, и работает он отлично.
Коротко об итогах
Мы поговорили о том, что корутины – это просто callback’и, которые по-хитрому подсовываются внутрь асинхронного метода, и не нужно их бояться или стесняться.
Убедились, что асинхронность позволяет избегать переключений контекста и создания новых потоков, экономя CPU. Такая модель подходит большему количеству языков программирования и приложений.
Также мы узнали, что под капотом у асинхронных движков находится жесть, и это прикольная жесть (если вам нравится таким заниматься). А снаружи у асинхронных корутиновых движков всё просто и более-менее понятно. Получается линейный код, в котором иногда надо расставить co_await, если у вас stackless-корутины, или ничего не надо расставлять, вы используете stackfull-корутины.
Во всех движках есть thread pool, очередь готовых к выполнению задач. Очередей может быть несколько, к примеру, у нас в userver есть отдельный thread pool для общения с операционной системой даже для неблокирующих вызовов, чтобы поскорее собирать события из ОС.
Надеюсь, материал оказался для вас полезным и интересным, стало понятнее, как всё устроено под капотом современных языков и фреймворков.
P. S. Кстати, уже в этом году мы перейдём на открытую разработку и опубликуем userver под лицензией Apache 2.0 на GitHub, чтобы им мог воспользоваться любой желающий. Надеемся, что вам понравится наша работа!
P. P. S. Эта статья – авторская переработка доклада с C++ Zero Cost Conf.